Robot Actions¶
This is why strands-diffusers exists. A world-foundation model like NVIDIA Cosmos
doesn't just generate a plausible future video - it predicts the robot action
chunk that produces it. use_diffusers serializes that chunk and can render it
so you can see the motion.

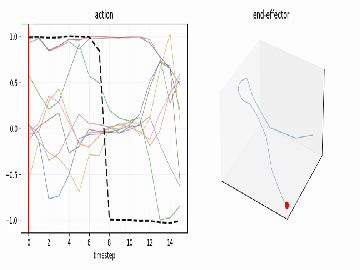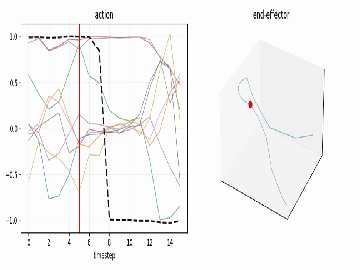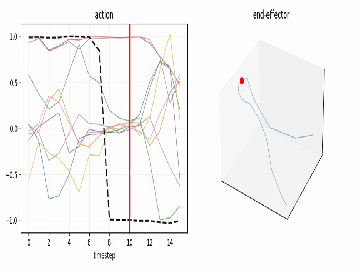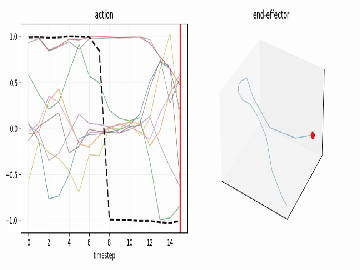
A reach-grasp-lift, visualized straight from the action tensor.

See an action chunk¶
from strands_diffusers import use_diffusers
# action shape: [num_chunks, T, action_dim] - a list, .json path, or cached:key
use_diffusers(action="visualize", inputs=action_chunk,
parameters={"fps": 8})
This produces three artifacts:
| time-series (every dim over time, gripper highlighted) | end-effector path (dims 0-2 integrated) |
|---|---|
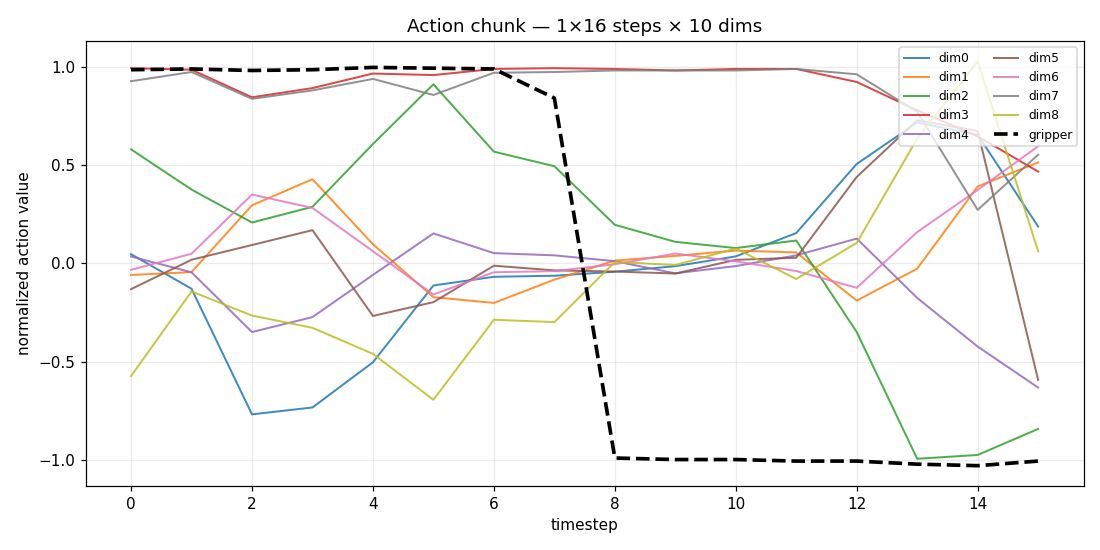 |
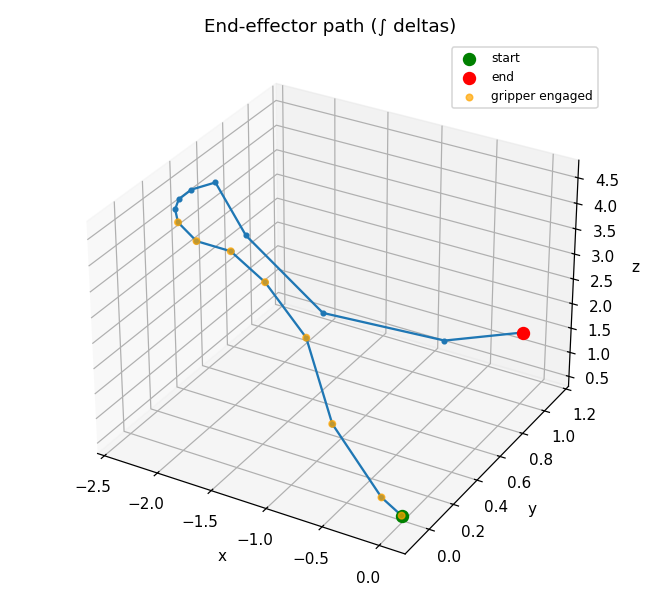 |
...plus an .mp4 animation sweeping a playhead across the curves - optionally
side-by-side with the generated world video frames.
The action payload¶
A Cosmos Cosmos3OmniPipelineOutput carries video, optional sound, and
action. The serializer writes each to the right artifact:
{
"type": "action",
"chunk_shape": [16, 10],
"num_chunks": 1,
"path": "/tmp/strands_diffusers/action_*.json"
}
The .json is the model-normalized action chunk (values in [-1, 1]) - feed it
straight to your embodiment's un-normalizer and controller. Values are preserved
exactly (no lossy clipping); bf16 tensors are upcast to f32 before serialization.
End to end¶
See World-Foundation Models for the full Cosmos action-policy rollout
that produces video and actions from one use_diffusers(action="run", ...)
call.