Quickstart¶
Prefer learning by doing?
Every concept below is also an interactive notebook with color-coded
diagrams — and they run safely even without a GPU. See Notebooks,
starting with notebooks/00_start_here.ipynb.
Get from zero to a running Cosmos agent in under 2 minutes.
The Journey¶
graph LR
A["1️⃣ Install"] --> B["2️⃣ Create Model"]
B --> C["3️⃣ Create Agent"]
C --> D["4️⃣ Ask Anything"]
style A fill:#1e3a5f,stroke:#60a5fa,color:#fff
style B fill:#76b900,stroke:#76b900,color:#fff
style C fill:#4a1d96,stroke:#a78bfa,color:#fff
style D fill:#92400e,stroke:#fbbf24,color:#fffInstall¶
Choose your path¶
| Goal | Use | Jump to |
|---|---|---|
| Understand and generate video/audio/action (latest) | Cosmos 3 | Cosmos 3 quickstart |
| Lightweight edge VLM (Jetson) | Cosmos-Reason2 | Reason2 quickstart |
Cosmos 3: Reason → Generate¶
Cosmos 3 is NVIDIA's newest omnimodal world model — one model that understands video/image and generates image, video, audio, and robot actions. See the full Cosmos 3 Guide.
Setup (one-time)¶
just c3-doctor # check GPU / CUDA / uv + recommended torch backend pairing
just c3-setup-reason # Reasoner env: vllm + vllm-cosmos3
just c3-setup-gen # Generator env: diffusers + cosmos_guardrail + soundfile
Or install the generator extras via pip:
Reason about a video¶
from strands import Agent
from strands_cosmos import Cosmos3ReasonerModel
agent = Agent(model=Cosmos3ReasonerModel(base_url="http://localhost:8000/v1"))
agent("Caption in detail: <video>scene.mp4</video>")
agent("List the notable events with timestamps: <video>scene.mp4</video>")
Generate video (and audio) from text¶
from strands_cosmos import Cosmos3GeneratorModel
gen = Cosmos3GeneratorModel(model_id="nvidia/Cosmos3-Nano")
gen.generate(mode="text2video", prompt="A robot navigates a warehouse aisle.",
out_path="vid.mp4", resolution="480")
gen.generate(mode="text2video-with-sound", prompt="A robot arm pours water.",
out_path="av.mp4", enable_sound=True) # H264 + AAC stereo 48kHz
Single-GPU note
The reasoner (vLLM) and generator (Diffusers) each load a 16B model — on one
~46GB GPU, stop one before running the other. CUDA pairing: CUDA 13 → cu130 +
vllm==0.21.0; CUDA 12.8 → cu128 + vllm==0.19.1. just c3-doctor reports it.
→ Reproduce the full reason→generate showcase: python examples/09_cosmos3_showcase.py
Cosmos-Reason2 (Edge VLM)¶
The lightweight VLM works straight from pip install strands-cosmos — ideal for
Jetson and quick local experiments.
1. Text-Only Physics Reasoning¶
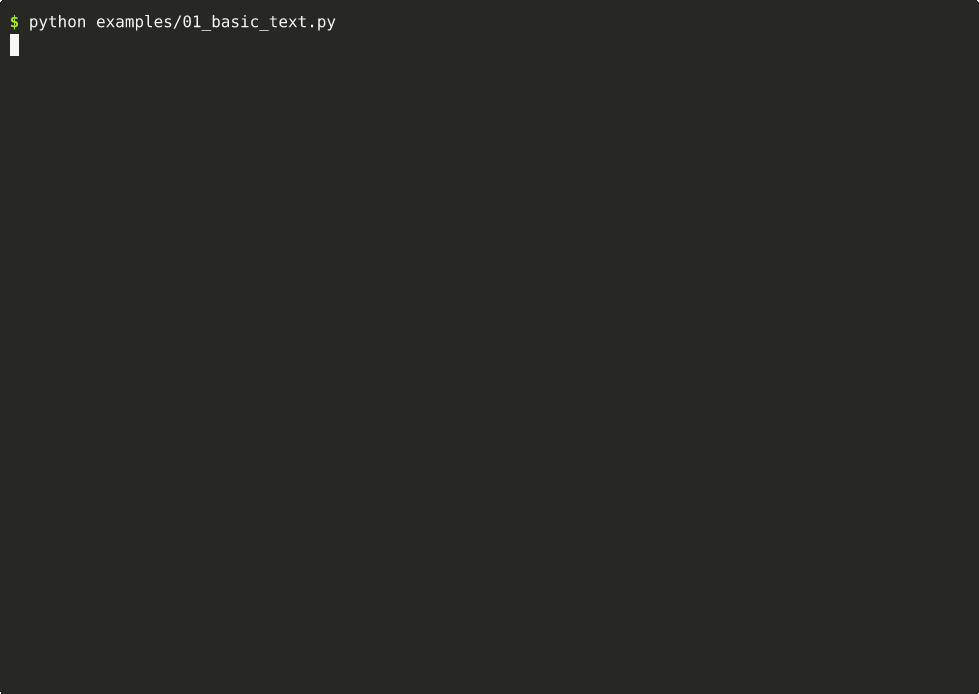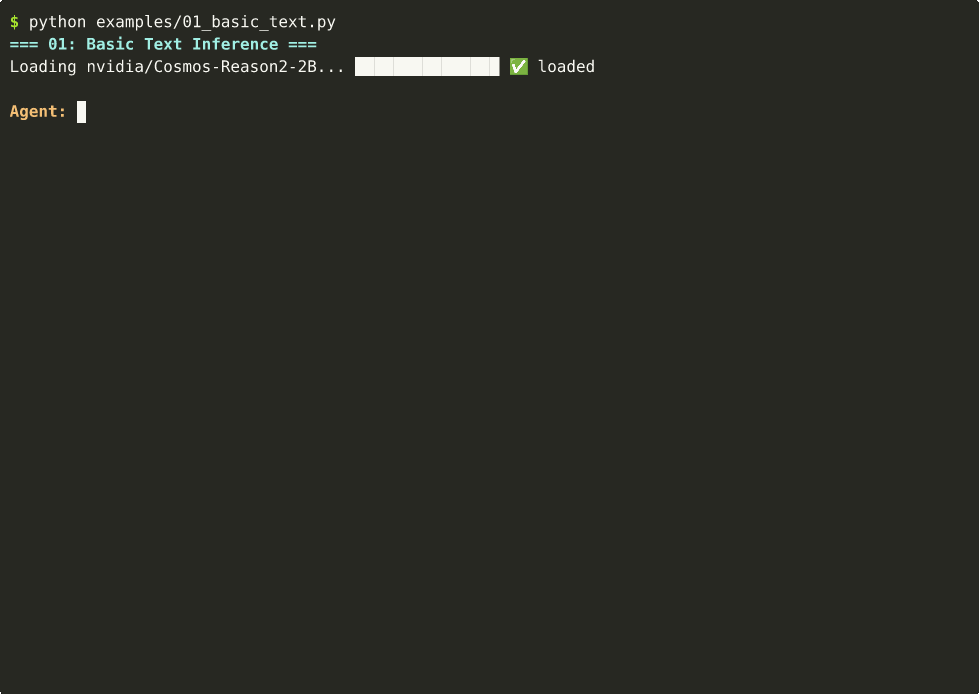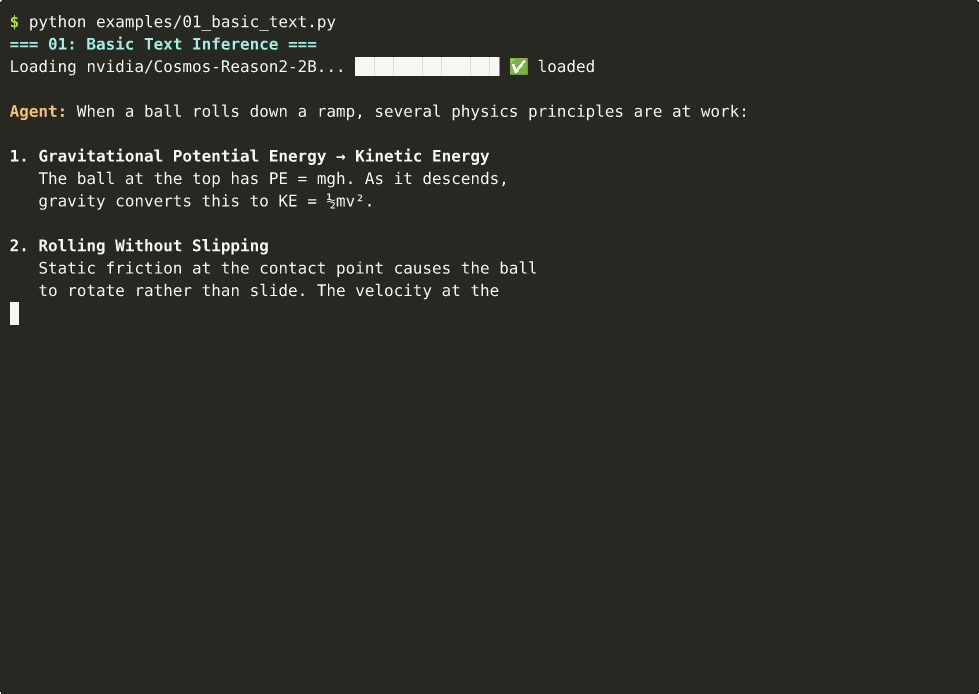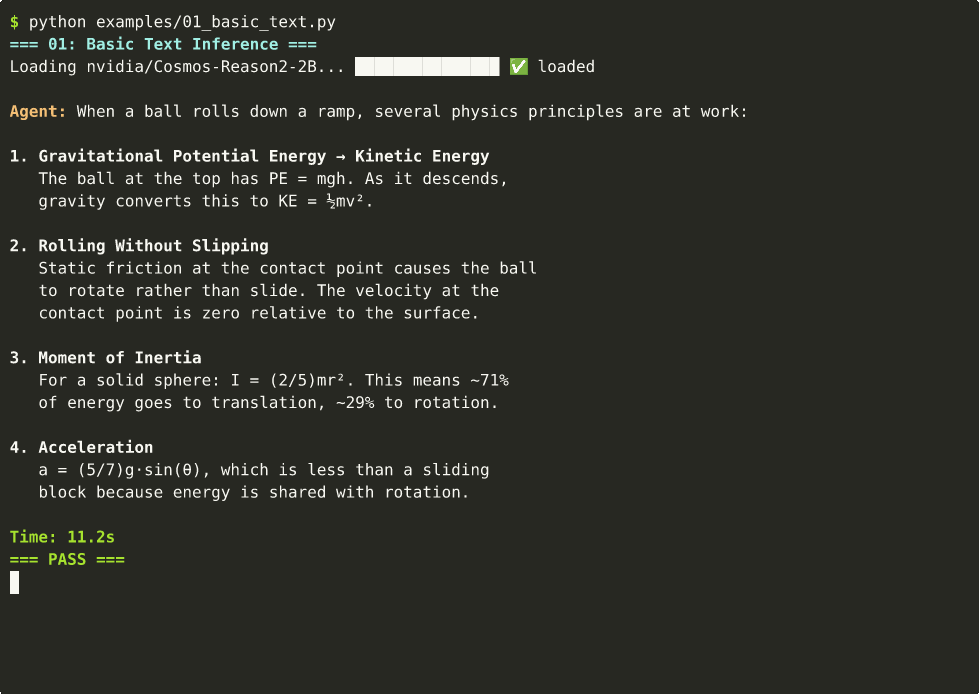
from strands import Agent
from strands_cosmos import CosmosVisionModel
model = CosmosVisionModel(model_id="nvidia/Cosmos-Reason2-2B")
agent = Agent(model=model)
result = agent("What happens when you push a ball off the edge of a table?")
2. Video Understanding¶
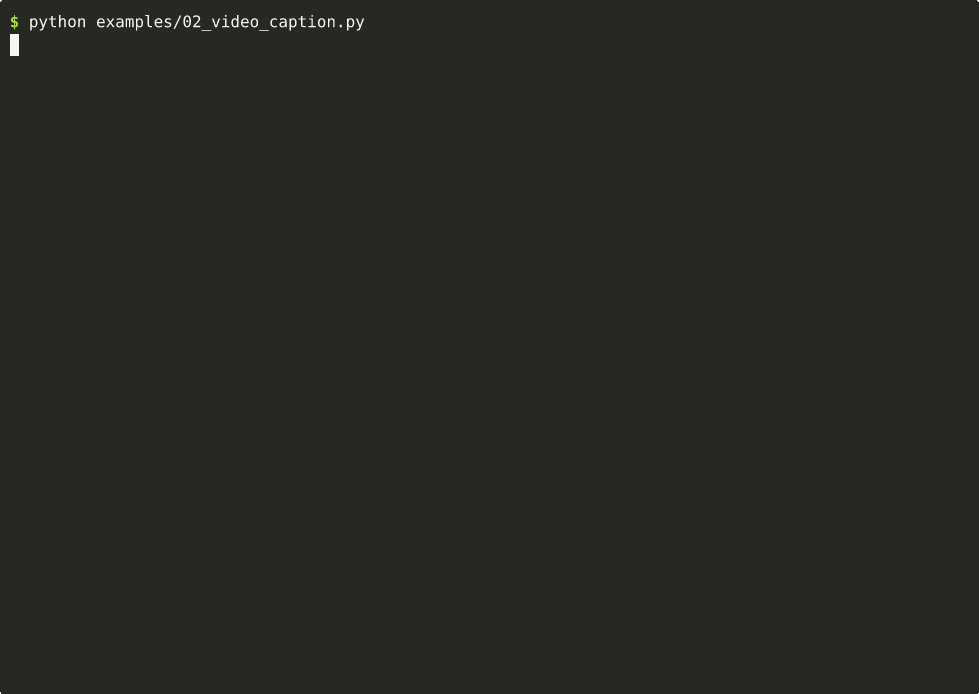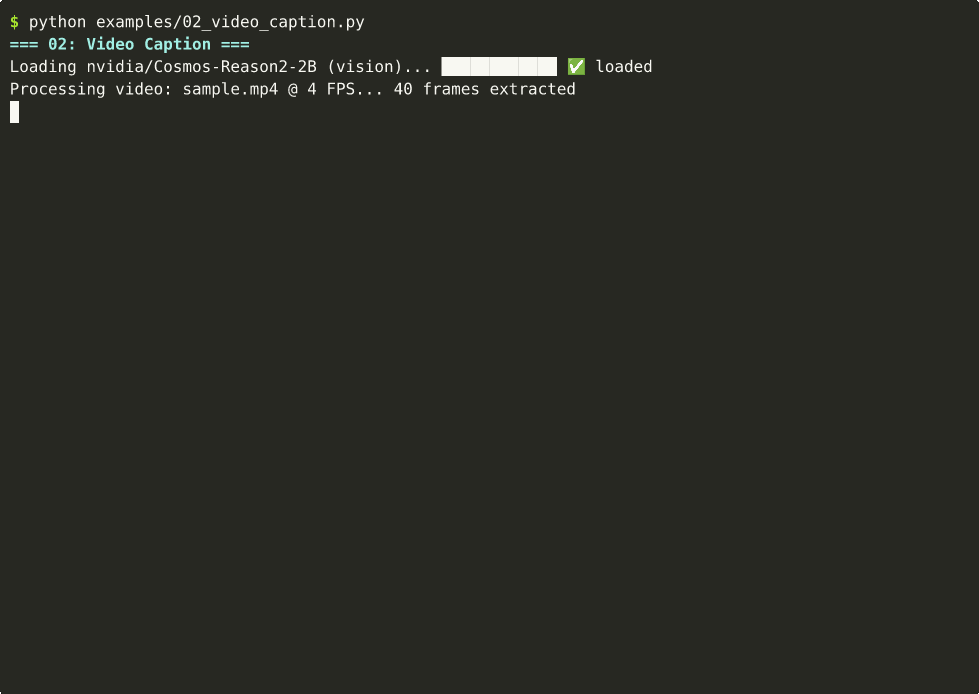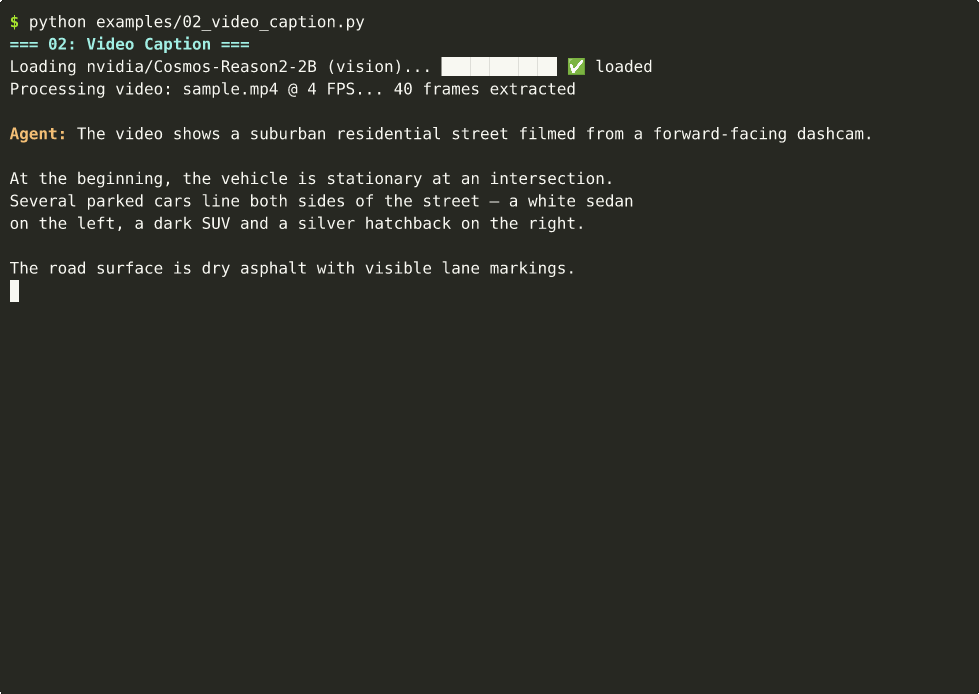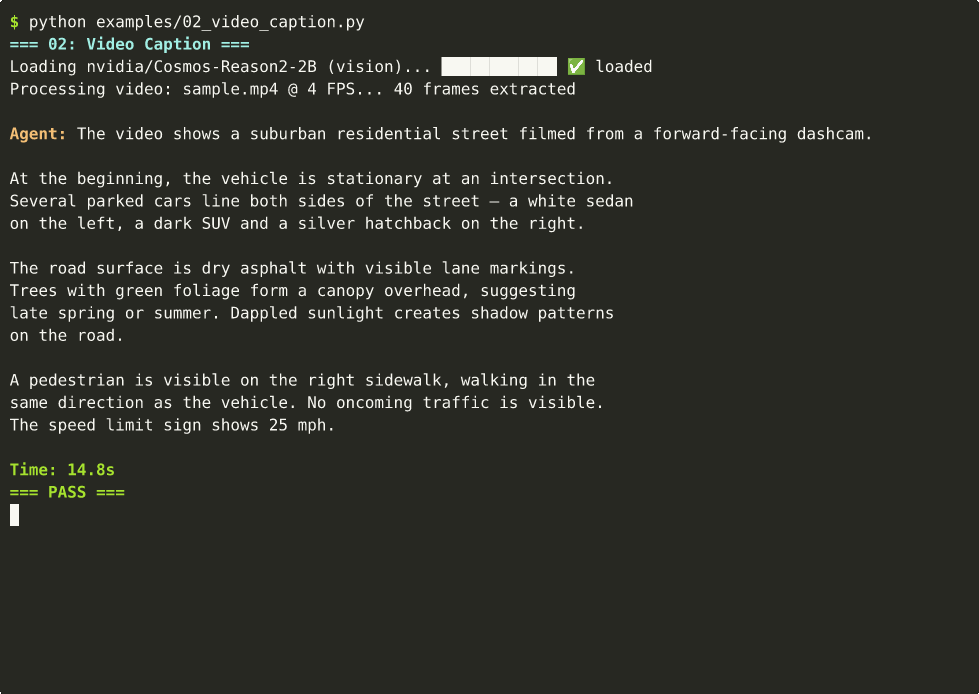
from strands import Agent
from strands_cosmos import CosmosVisionModel
model = CosmosVisionModel(
model_id="nvidia/Cosmos-Reason2-2B",
fps=4,
params={"max_tokens": 4096},
)
agent = Agent(model=model)
# Inline video reference
agent("Caption this video in detail: <video>dashcam.mp4</video>")
How It Works¶
sequenceDiagram
participant You as 🧑 You
participant Agent as 🤖 Strands Agent
participant Cosmos as 🌌 Cosmos-Reason2
You->>Agent: "Caption: <video>dashcam.mp4</video>"
Agent->>Cosmos: Extract frames @ 4 FPS
Cosmos->>Cosmos: Visual tokens + text tokens
Cosmos->>Cosmos: Autoregressive generation
Cosmos-->>Agent: Detailed scene description
Agent-->>You: Response text3. Image Reasoning¶
4. Chain-of-Thought Reasoning¶
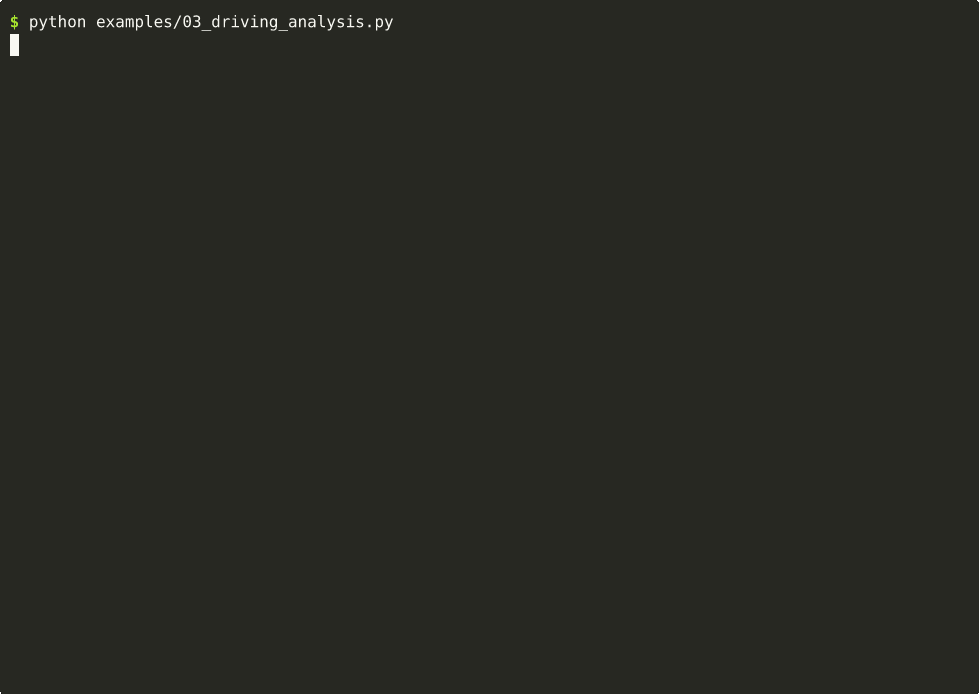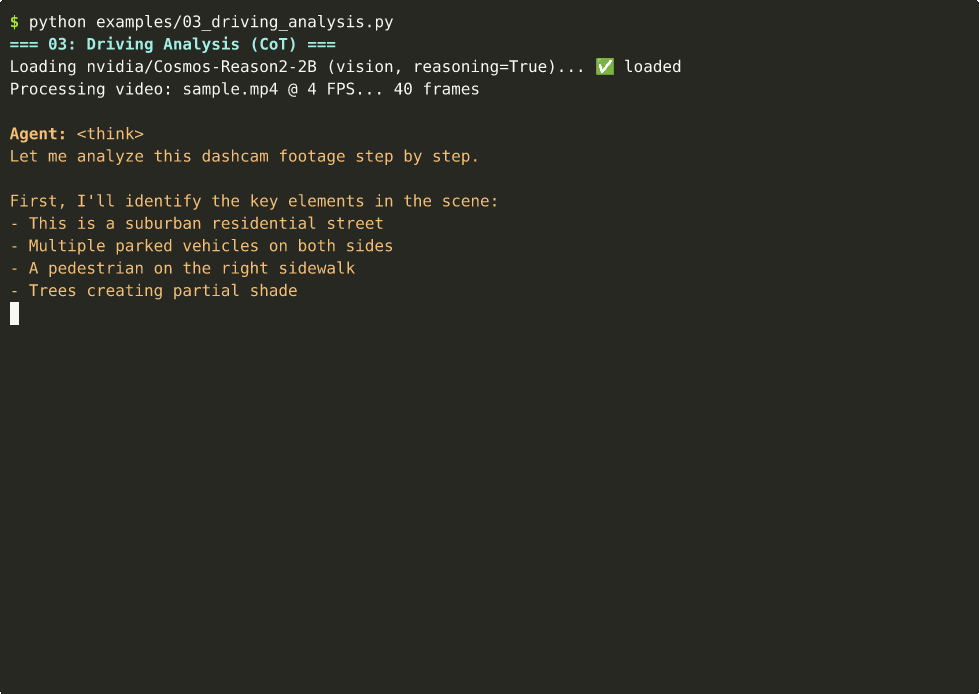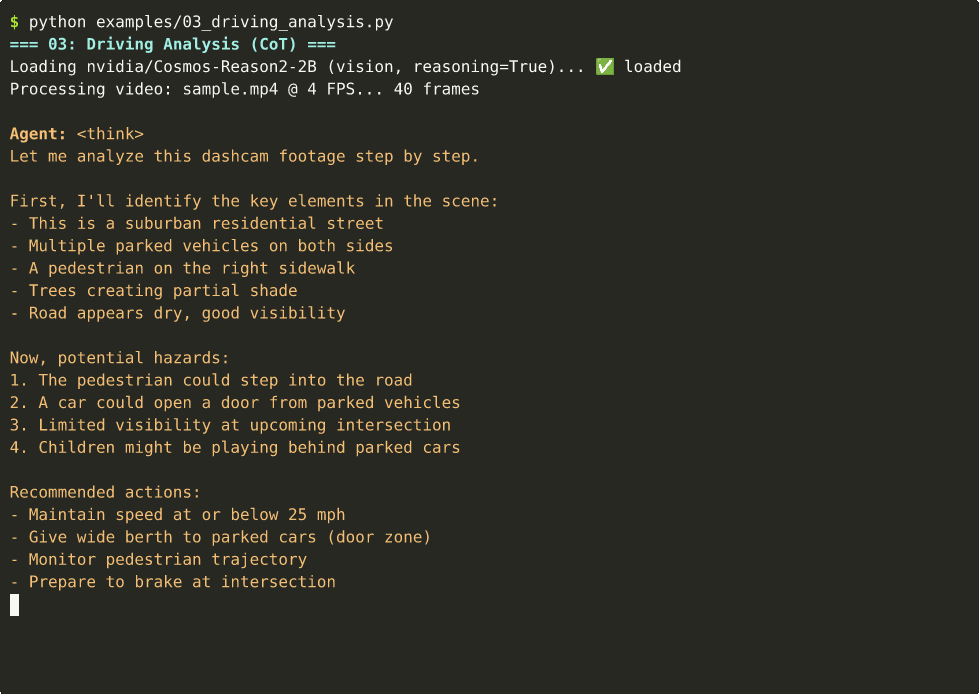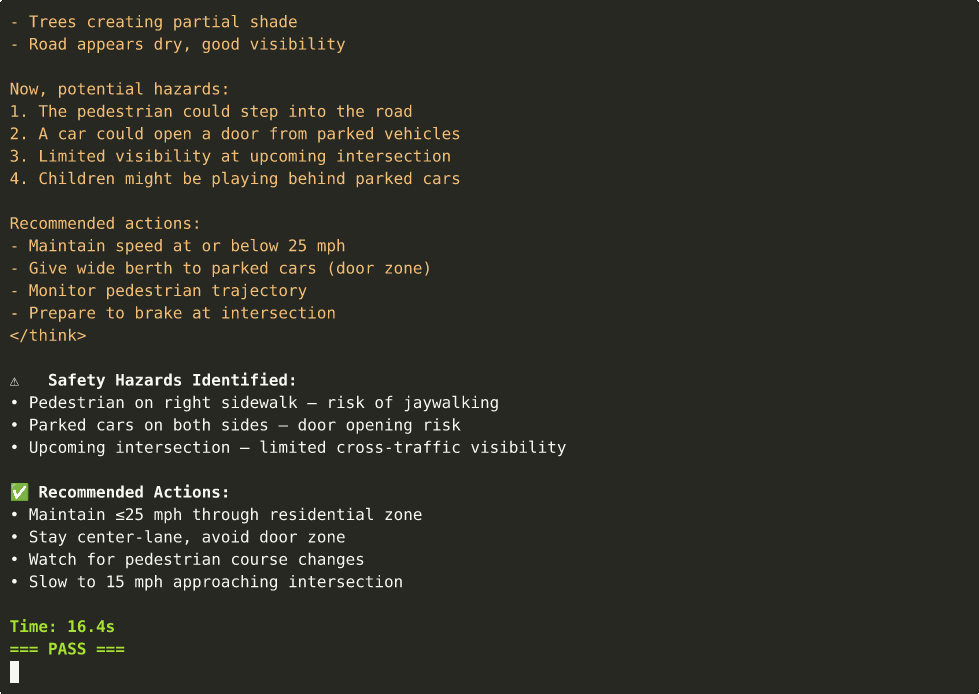
model = CosmosVisionModel(
model_id="nvidia/Cosmos-Reason2-2B",
reasoning=True, # Enables <think>...</think>
)
agent = Agent(model=model)
# The model reasons step-by-step before answering
agent("<video>intersection.mp4</video> Analyze the safety situation.")
5. As a Tool (Inside Another Agent)¶
from strands import Agent
from strands_cosmos import cosmos_vision_invoke
# Cosmos becomes a tool inside a Bedrock / OpenAI / Ollama agent
agent = Agent(tools=[cosmos_vision_invoke])
agent("Analyze this dashcam video for safety hazards: /path/to/video.mp4")
Tool Usage
When used as a tool, Cosmos runs locally on GPU while the orchestrating agent can be any provider (Bedrock, Anthropic, OpenAI, etc.). See Tool Usage Guide.
What's Next¶
graph LR
QS["✅ You are here:<br/>Quickstart"] --> V["🎬 Video<br/>Understanding"]
QS --> C["🧠 Chain-of-<br/>Thought"]
QS --> T["🔧 Tool<br/>Usage"]
QS --> J["🔲 Jetson<br/>Deployment"]
style QS fill:#76b900,stroke:#76b900,color:#fff
style V fill:#1e3a5f,stroke:#60a5fa,color:#fff
style C fill:#4a1d96,stroke:#a78bfa,color:#fff
style T fill:#92400e,stroke:#fbbf24,color:#fff
style J fill:#831843,stroke:#f472b6,color:#fff- Video Understanding — Process dashcam, robot, and scene videos
- Chain-of-Thought — Enable step-by-step reasoning
- Tool Usage — Use Cosmos inside any agent
- Jetson Deployment — Run on NVIDIA Jetson edge devices
- Cosmos 3 Guide — Omnimodal reasoning + generation (video/audio/action)