Strands Cosmos
NVIDIA Cosmos for Strands Agents — omnimodal world-model reasoning and generation, on local compute.
Cosmos models become first-class Strands model providers: give your agent eyes that understand physics, and hands that can generate video, audio, and robot actions — plus 45 tools spanning the full Cosmos pipeline.
| Family | Providers | Best for |
|---|---|---|
| Cosmos 3 (latest, omnimodal) | Cosmos3ReasonerModel, Cosmos3GeneratorModel |
Video/image/audio/action understanding + generation |
| Cosmos-Reason2 (VLM) | CosmosVisionModel, CosmosModel |
Lightweight edge VLM (Jetson Thor/Orin) |
🌌 Cosmos 3 — Reason → Generate¶
Cosmos 3 is NVIDIA's newest model family — a unified Mixture-of-Transformers that jointly understands and generates text, images, video, audio, and action. Here it watches a real construction-site clip, describes it, then generates new videos (one with synchronized audio) from its own description — all on a single local GPU.
| ① Input video | ② Cosmos 3 understands it |
|---|---|
 |
> *"Two construction workers wearing yellow safety vests and helmets are walking away from the camera on a dirt path within a bustling construction site. The ground is covered in loose soil, with visible tire tracks crisscrossing the surface. In the background, a large yellow front-end loader moves slowly across the site, its bucket raised slightly as it navigates the terrain. Behind the loader, partially obscured by rebar and concrete slabs, an excavator operates near a foundation area. The scene is framed by urban buildings in the distance, including a distinctive church-like structure with a tall spire and modern glass-fronted buildings. The overall atmosphere suggests active progress on a significant infrastructure project under clear daylight conditions."* — `Cosmos3ReasonerModel` (caption in 5.2s) |
The reasoner distills its own understanding into a generation prompt:
"Two construction workers in yellow safety vests and helmets walk across a dusty site, gesturing toward a yellow front loader and distant excavator as they converse."
Then Cosmos3GeneratorModel generates similar videos from that prompt (832×480, 49 frames):
| text → video | text → video + 🔊 sound | image → video |
|---|---|---|
 |
 |
 |
| 55.5s | 43.2s · AAC stereo 48kHz | 42.1s · from a real frame |
→ Full walkthrough: Cosmos 3 Guide · reproduce with python examples/09_cosmos3_showcase.py
from strands import Agent
from strands_cosmos import Cosmos3ReasonerModel, Cosmos3GeneratorModel
# Reasoner — text + vision -> text (local vLLM; start with `just c3-serve-reason`)
agent = Agent(model=Cosmos3ReasonerModel(base_url="http://localhost:8000/v1"))
agent("Caption in detail: <video>scene.mp4</video>")
# Generator — text/image -> image/video/sound (in-process Diffusers, no server)
gen = Cosmos3GeneratorModel(model_id="nvidia/Cosmos3-Nano")
gen.generate(mode="text2video-with-sound", prompt="A robot pours water.",
out_path="av.mp4", enable_sound=True) # H264 + AAC stereo 48kHz
Single-GPU note
The reasoner (vLLM) and generator (Diffusers) each load a 16B model — on one
~46GB GPU, stop one before running the other. CUDA pairing: CUDA 13 → cu130 +
vllm==0.21.0. just c3-doctor reports your driver's recommendation.
Cosmos-Reason2 — Lightweight Edge VLM¶
For edge/Jetson, the Cosmos-Reason2 VLM runs as a model provider with a tiny footprint — verified on Jetson AGX Thor with Chain-of-Thought reasoning.
-
🚗 Driving Analysis with Chain-of-Thought
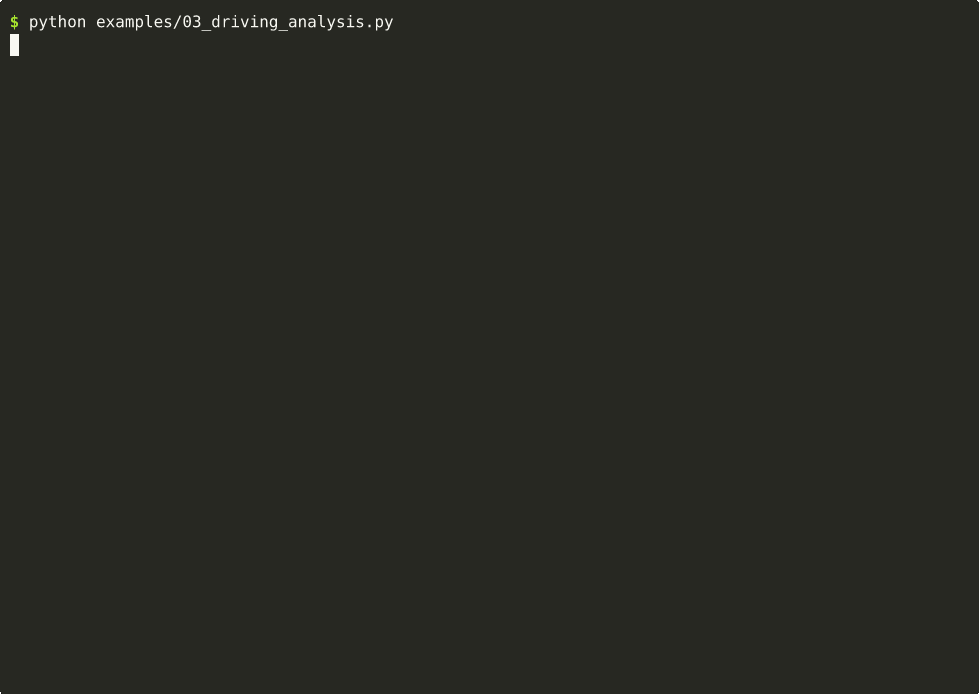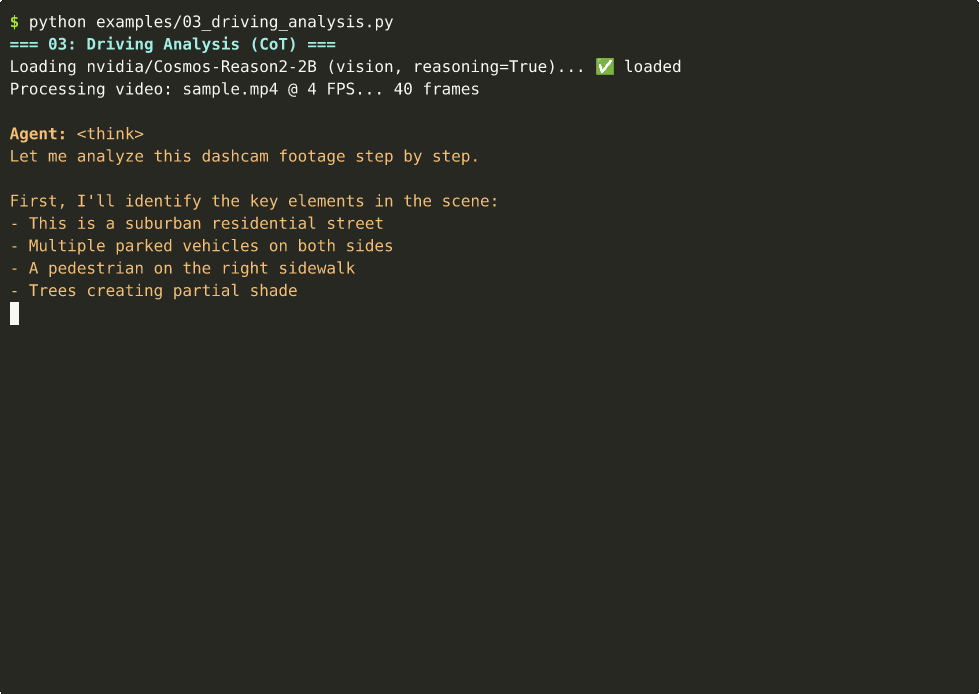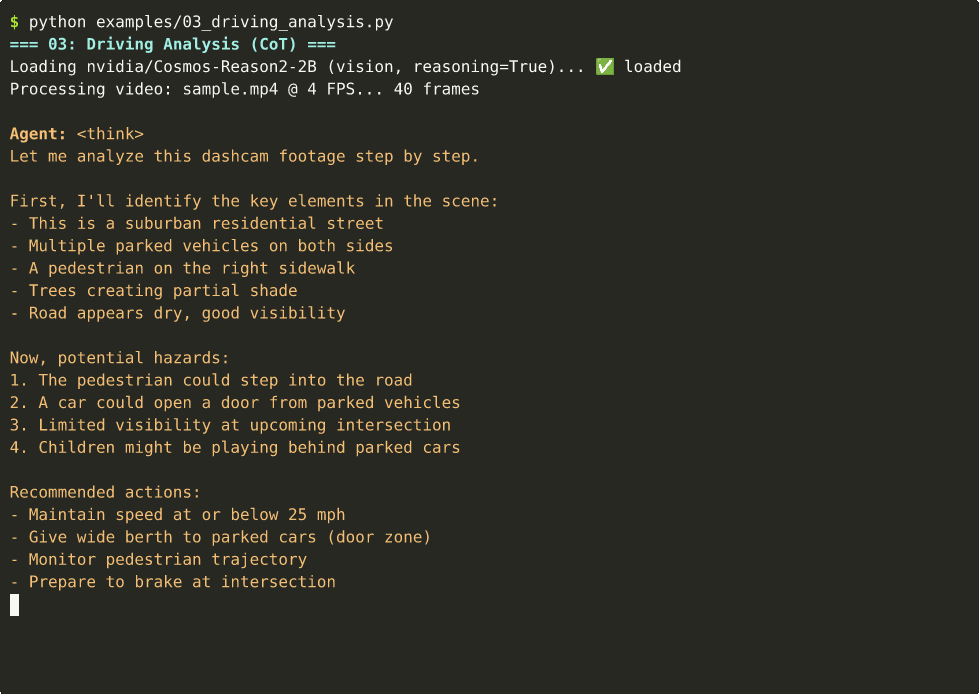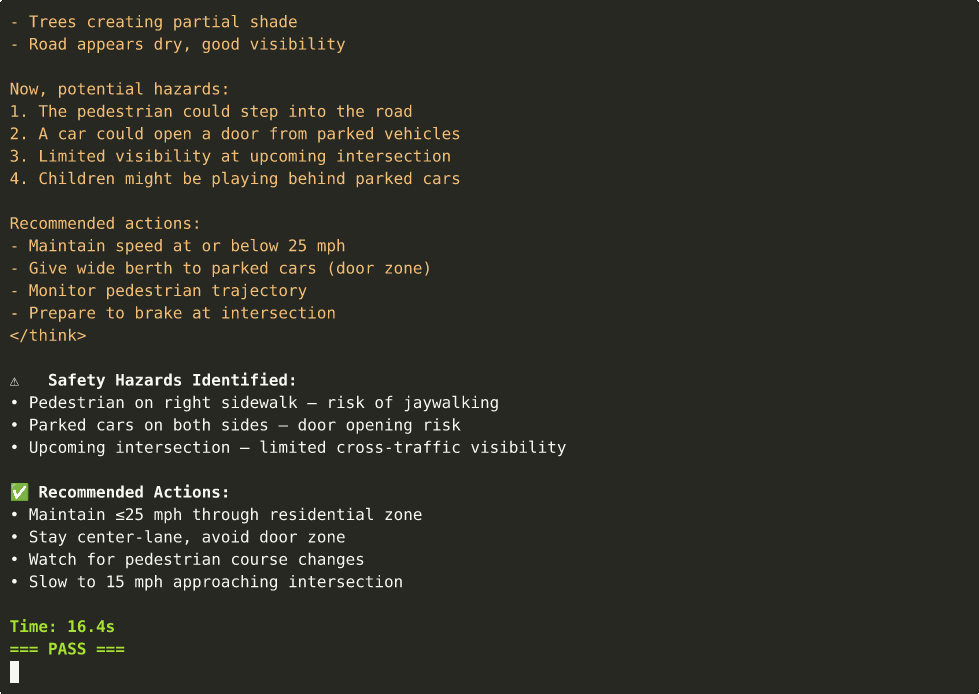
-
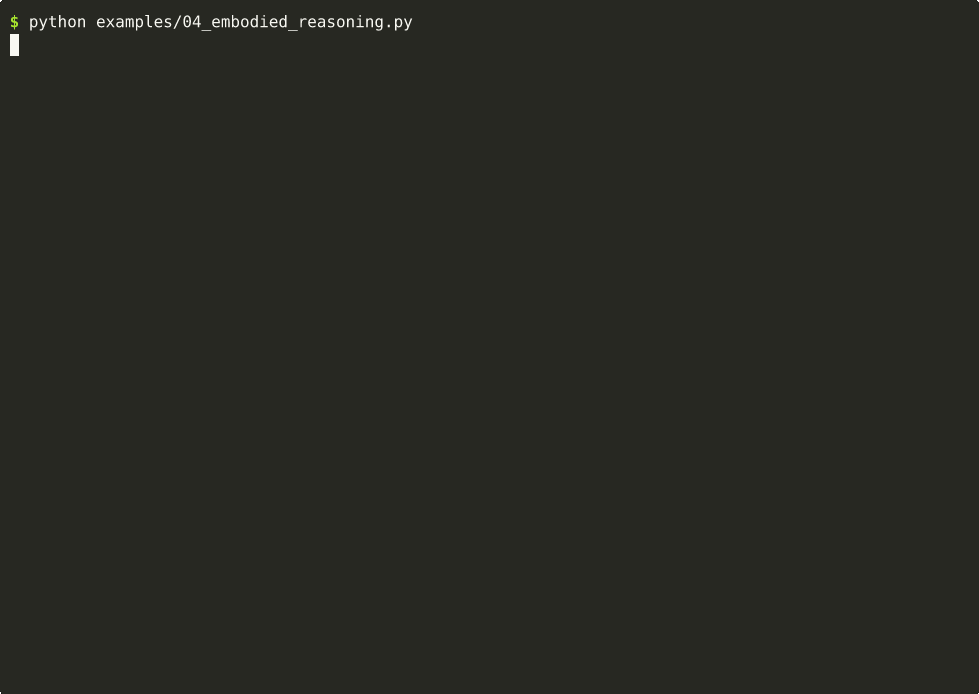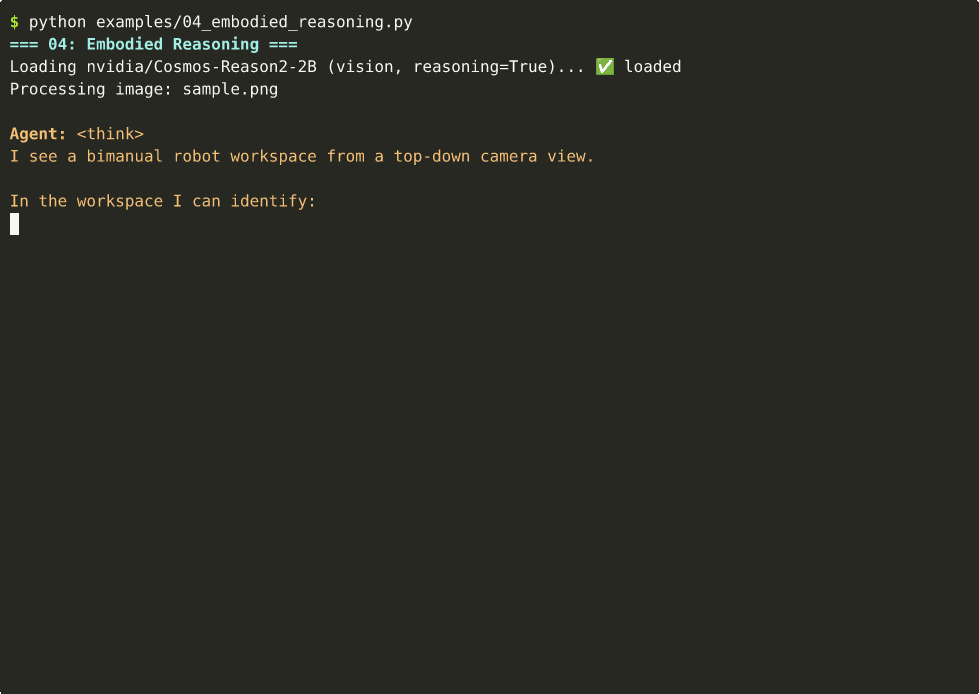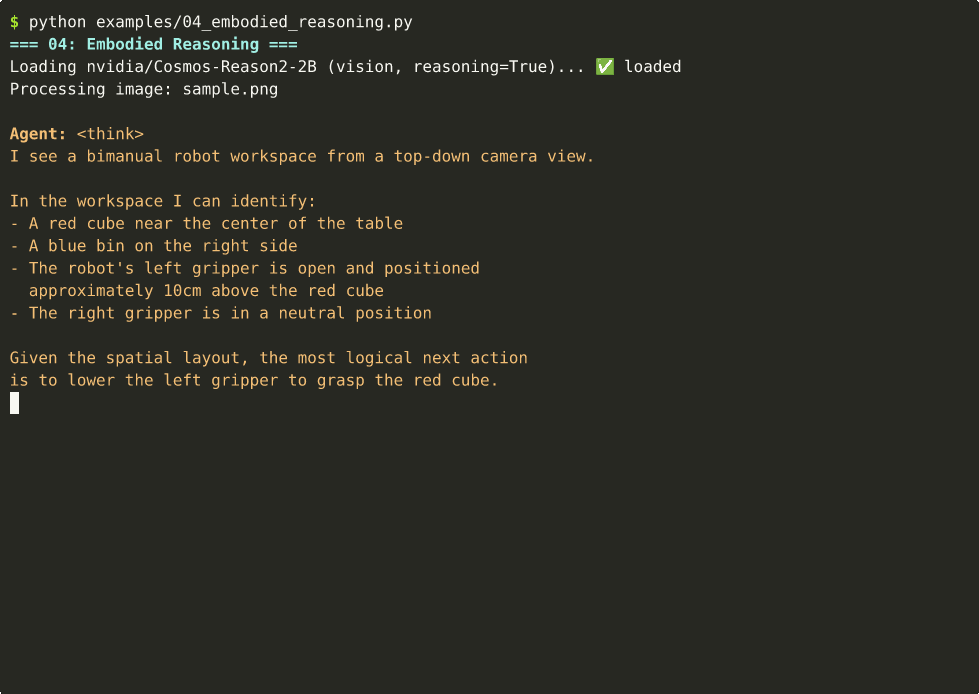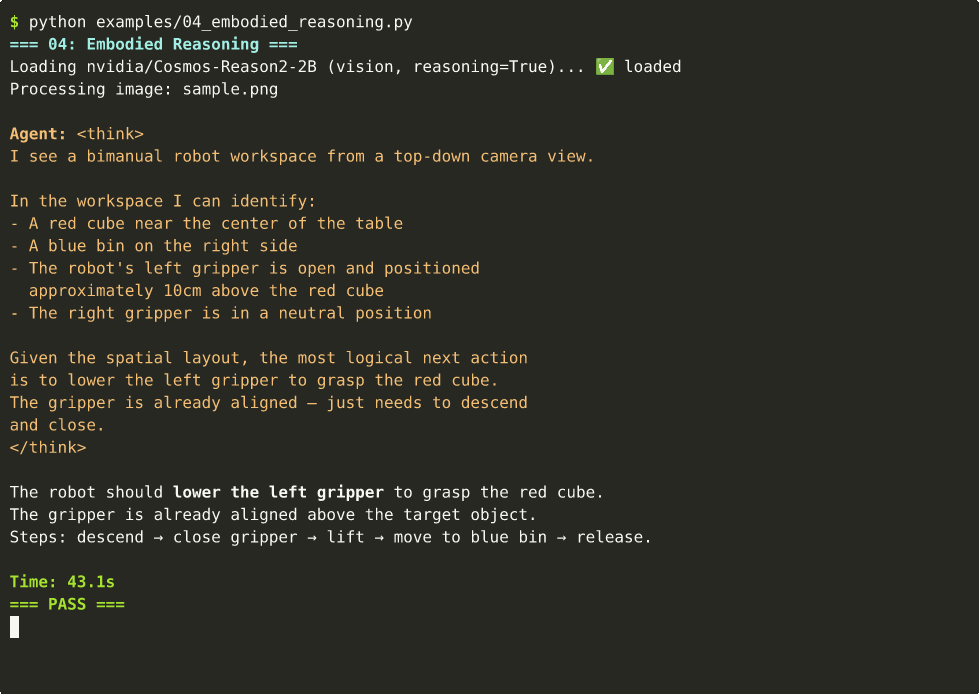
🤖 Robot Embodied Reasoning
-
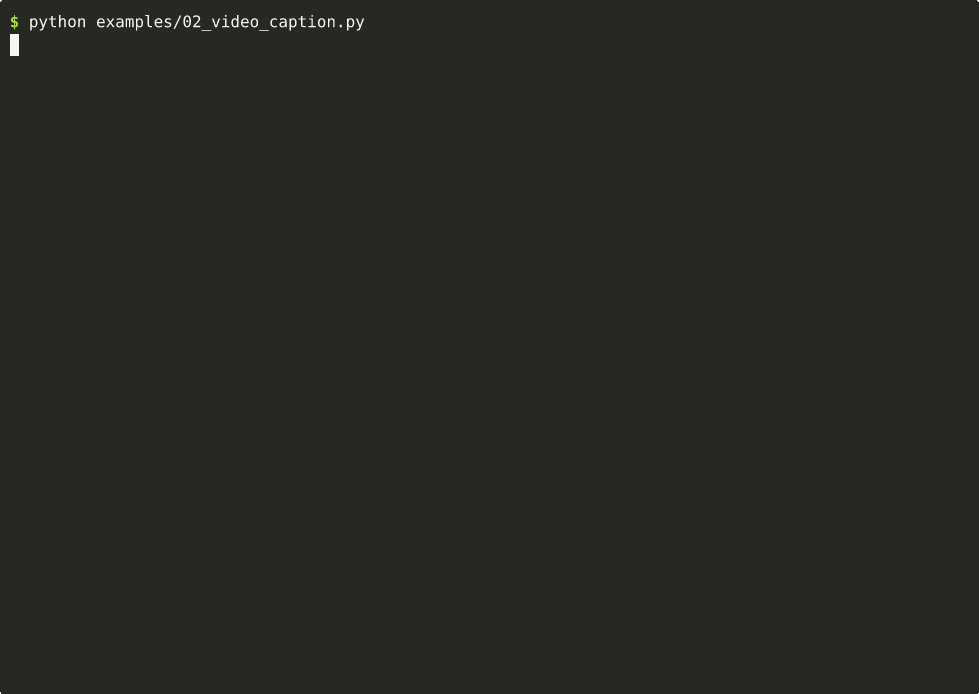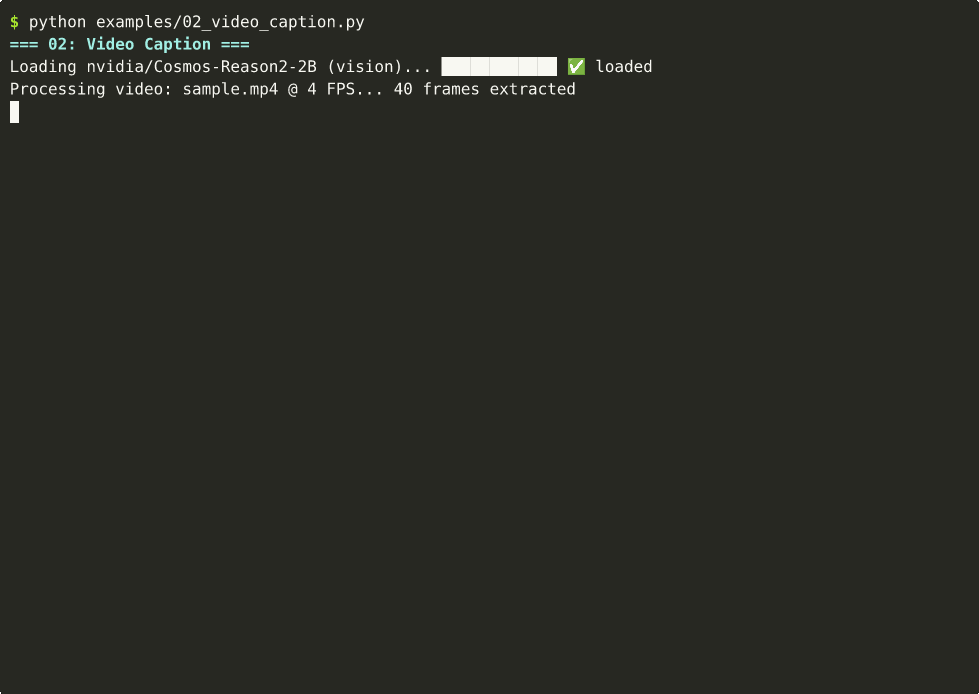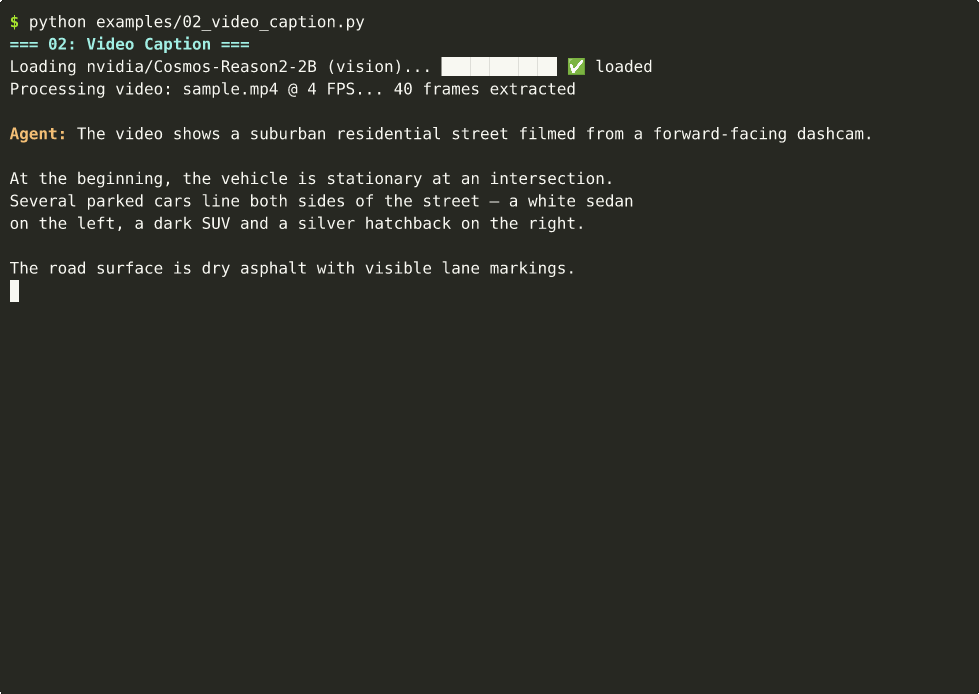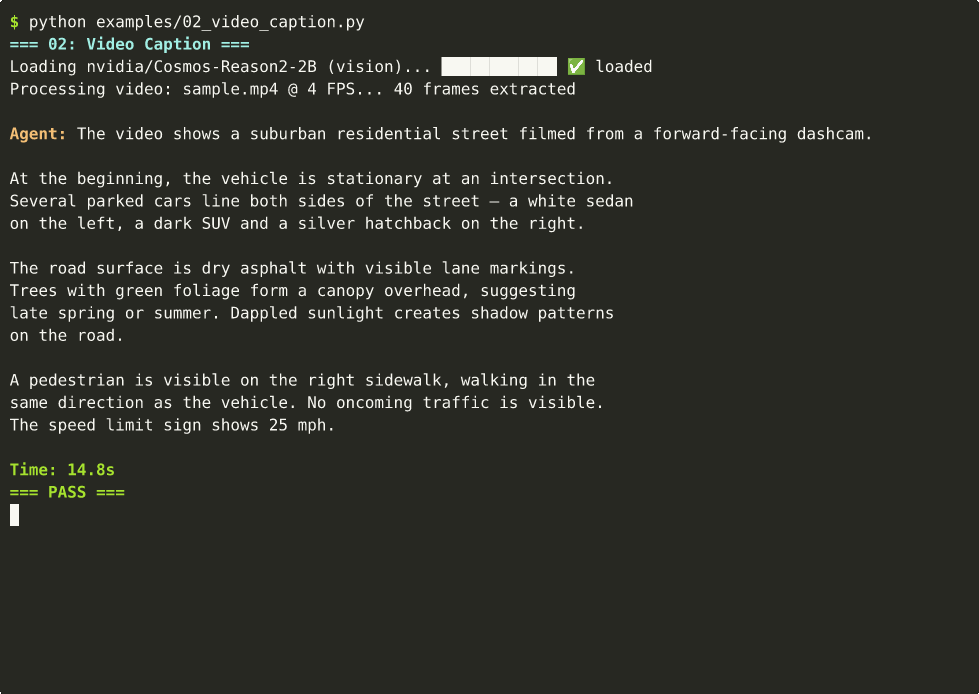
🎬 Video Captioning
-
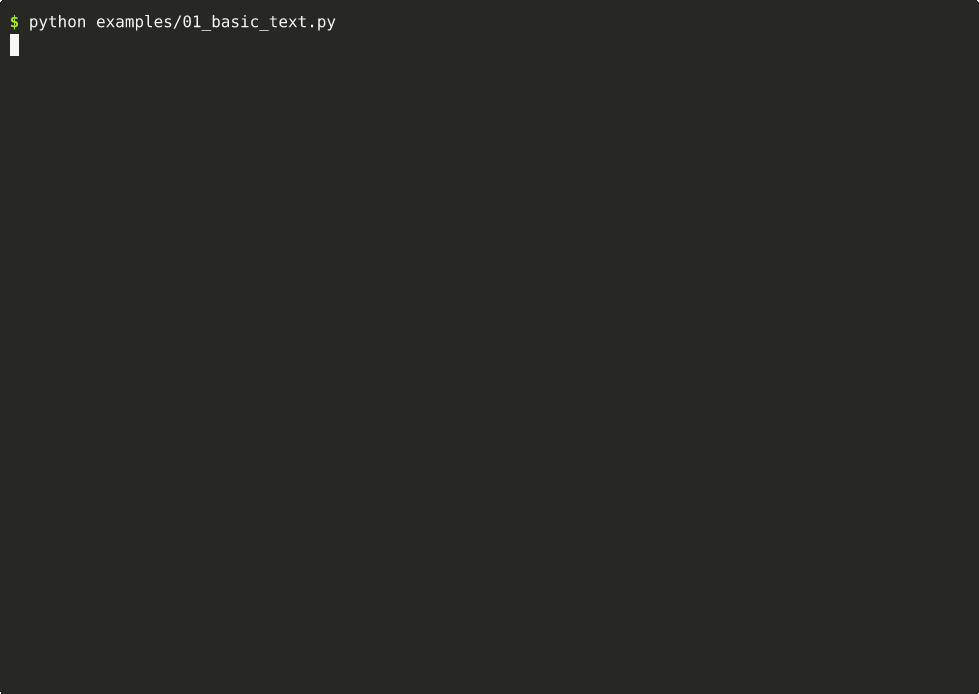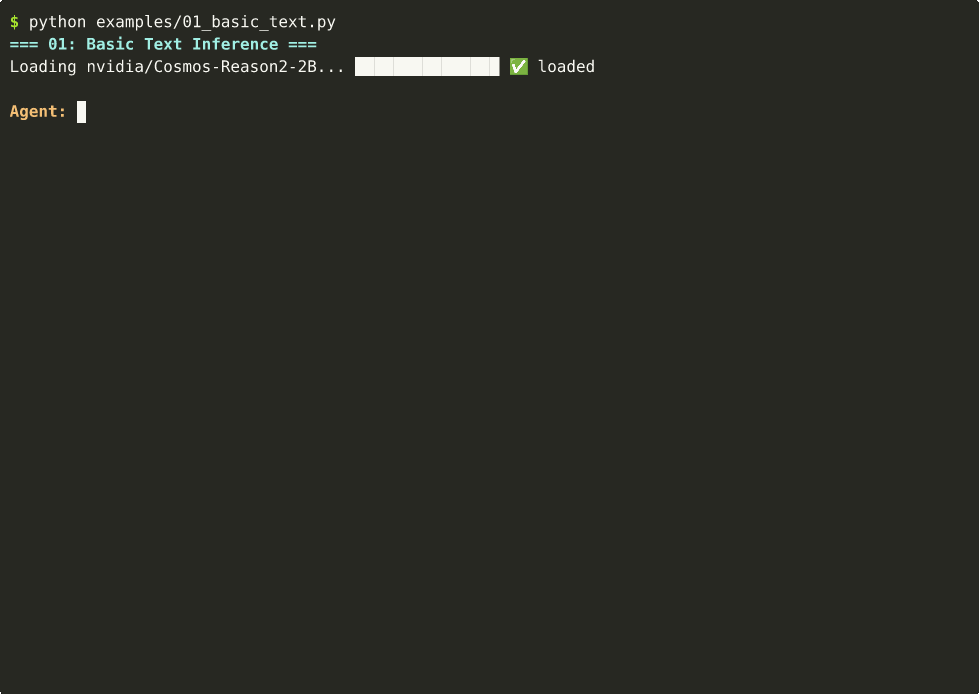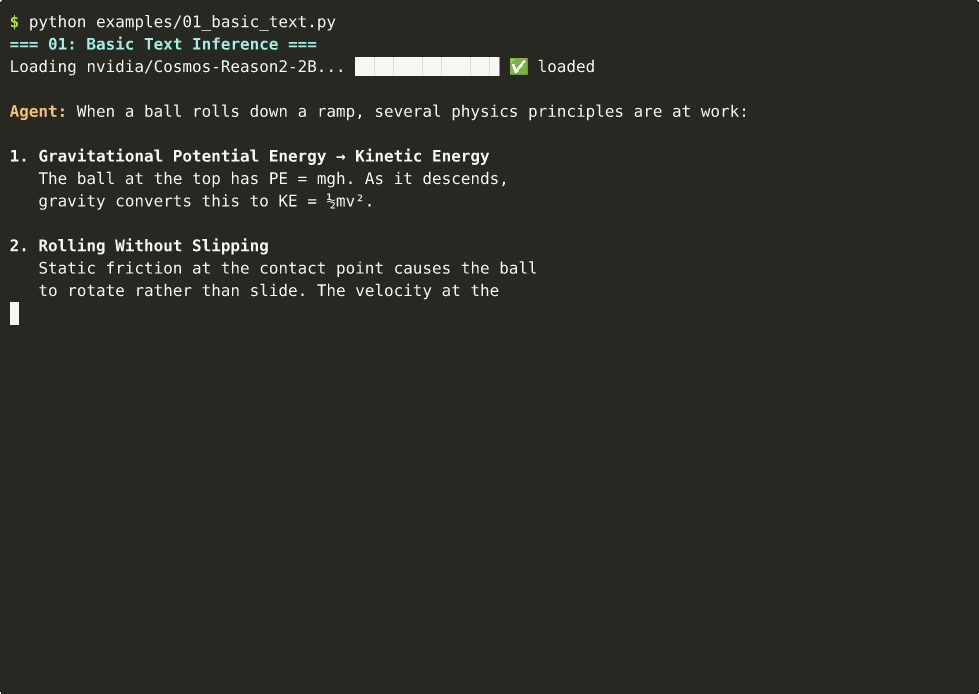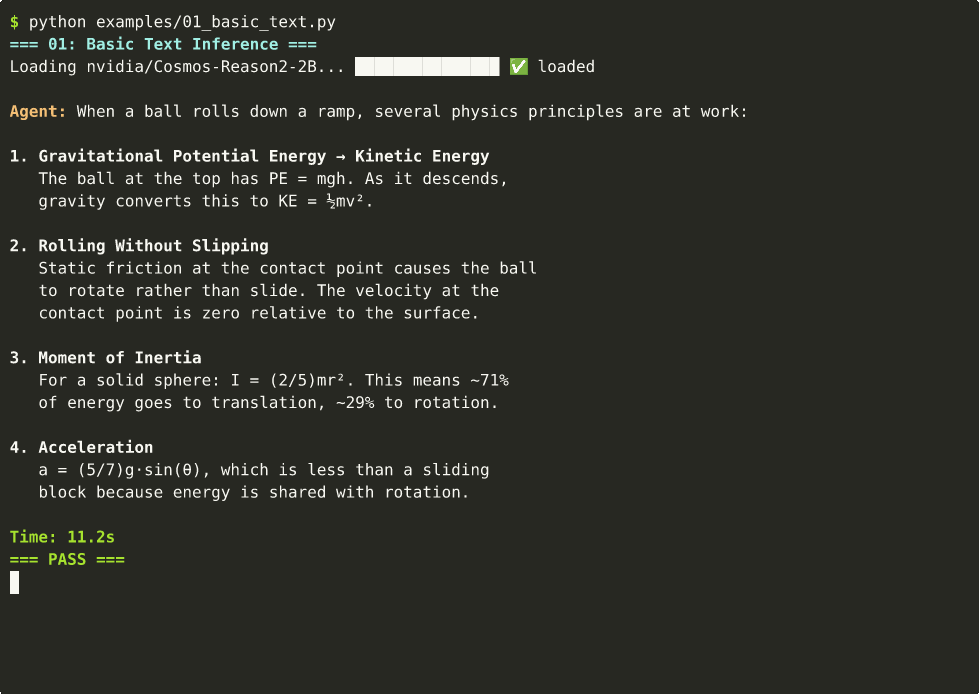
⚛️ Physics Reasoning (Text-Only)
graph LR
A["🗣️ Strands Agent"] --> RCosmos 3
R -->|Reasoner| U["📹 Understand: caption · temporal · embodied · grounding"]
R -->|Generator| G["🎬 Generate: image · video · 🔊 audio · 🤖 action"]
A --> VCosmos-Reason2 VLM
V -->|Edge| E["🚗 Driving · Robot planning · CoT"]Get Started in 2 Minutes¶
For Cosmos 3, see the Cosmos 3 Guide (just c3-setup-reason / just c3-setup-gen).
For the Reason2 edge VLM, it works straight from pip:
from strands import Agent
from strands_cosmos import CosmosVisionModel
model = CosmosVisionModel(model_id="nvidia/Cosmos-Reason2-2B")
agent = Agent(model=model)
# Analyze a dashcam video
agent("Caption in detail: <video>dashcam.mp4</video>")
# Reason about a robot's view
agent("<image>robot_view.jpg</image> What should the robot do next?")
# Physics understanding (text-only)
agent("What happens when you push a ball off the edge of a table?")
→ Full Quickstart | Installation
Capabilities¶
-
🚗 Driving Analysis
Traffic, hazards, navigation from dashcam video
-
🤖 Robot Planning
Next-action prediction, 2D trajectory planning
-
🎬 Video Captioning
Detailed temporal-spatial descriptions
-
⚛️ Physics Reasoning
Object permanence, causality, plausibility
-
🔍 2D Grounding
Bounding box localization in images
-
🧠 Chain-of-Thought
<think>reasoning before answers
Models¶
Cosmos 3 (omnimodal — reasoning + generation):
| Model | Size | Capability |
|---|---|---|
| Cosmos3-Nano | 16B | Omnimodal (reasoner + generator + action) — fits a single ~46GB GPU |
| Cosmos3-Super | 64B | Frontier-scale (multi-GPU / tensor-parallel) |
| Cosmos3-Nano-Policy-DROID | 16B | VL robot policy (DROID) |
Cosmos-Reason2 (lightweight edge VLM):
| Model | GPU Memory | Architecture | Best For |
|---|---|---|---|
| Cosmos-Reason2-2B | 24 GB | Qwen3-VL | Edge / Jetson |
| Cosmos-Reason2-8B | 32 GB | Qwen3-VL | Desktop / Cloud |
Verified Platforms¶
| Platform | GPU | Status |
|---|---|---|
| Jetson AGX Thor | Thor 132 GB | ✅ (with CUBLAS fix) |
| Desktop | A100 / H100 / RTX 4090 | ✅ |
| Jetson Orin | Orin 32/64 GB | ✅ (may need CUBLAS fix) |
Two Ways to Use¶
from strands import Agent
from strands_cosmos import (
cosmos_model_download, cosmos_quantize, cosmos_export_onnx,
cosmos_build_engine, cosmos_serve, cosmos_inference,
)
# Agent orchestrates the full edge-deployment pipeline
agent = Agent(tools=[
cosmos_model_download, cosmos_quantize, cosmos_export_onnx,
cosmos_build_engine, cosmos_serve, cosmos_inference,
])
agent("Download Reason2-2B, quantize to FP8, export ONNX, build TRT engine, start server, and run a test query")
Performance on Jetson AGX Thor¶
Benchmarks with Cosmos-Reason2-2B on 132GB unified memory:
| Example | Task | Time | Recording |
|---|---|---|---|
| 01 | Text-only physics | ~11s | cast |
| 02 | Video caption (10s @ 4fps) | ~15s | cast |
| 03 | Driving analysis + CoT | ~16s | cast |
| 04 | Embodied reasoning + CoT | ~43s | cast |
| 05 | Tool invocation | ~9s | cast |
Quick Links¶
Developer Setup (Full Cosmos Ecosystem)¶
git clone https://github.com/cagataycali/strands-cosmos && cd strands-cosmos
just setup-full # Installs apt deps, Python deps, clones 6 Cosmos repos
just doctor # Platform diagnostics — what works on THIS machine
just doctor checks: repos, core tools, Python packages, media tools, TRT binaries, GPU/CUDA — with platform-aware guidance (workstation vs Jetson vs Docker).