Examples¶
Runnable examples tested on NVIDIA Jetson AGX Thor (132GB unified memory).
Demo Video¶

Click to watch the full demo video
All Examples¶
-
01 — Basic Text (Physics Reasoning)
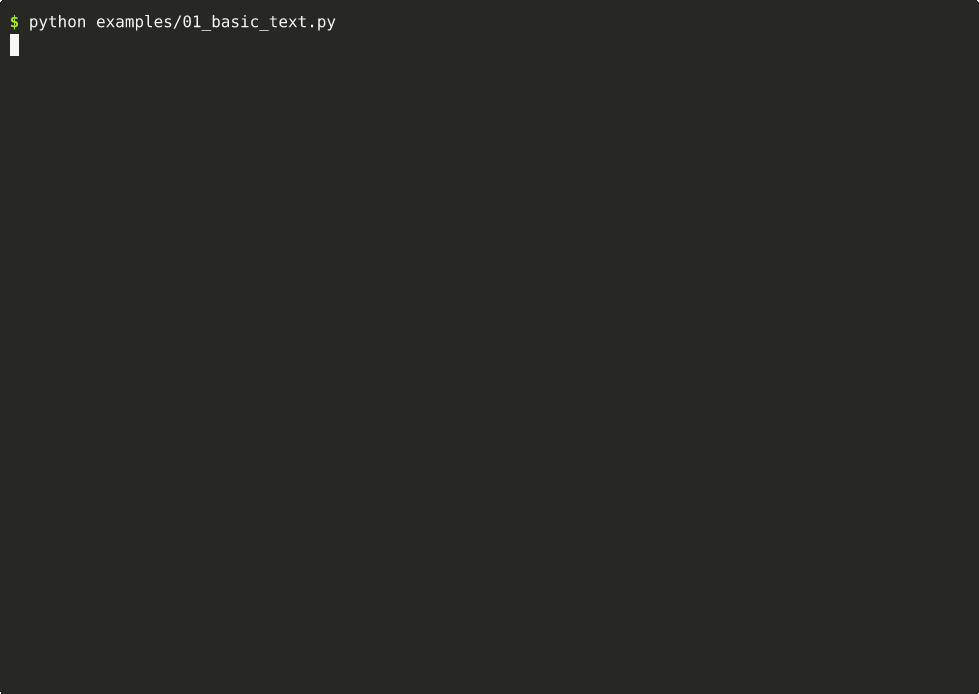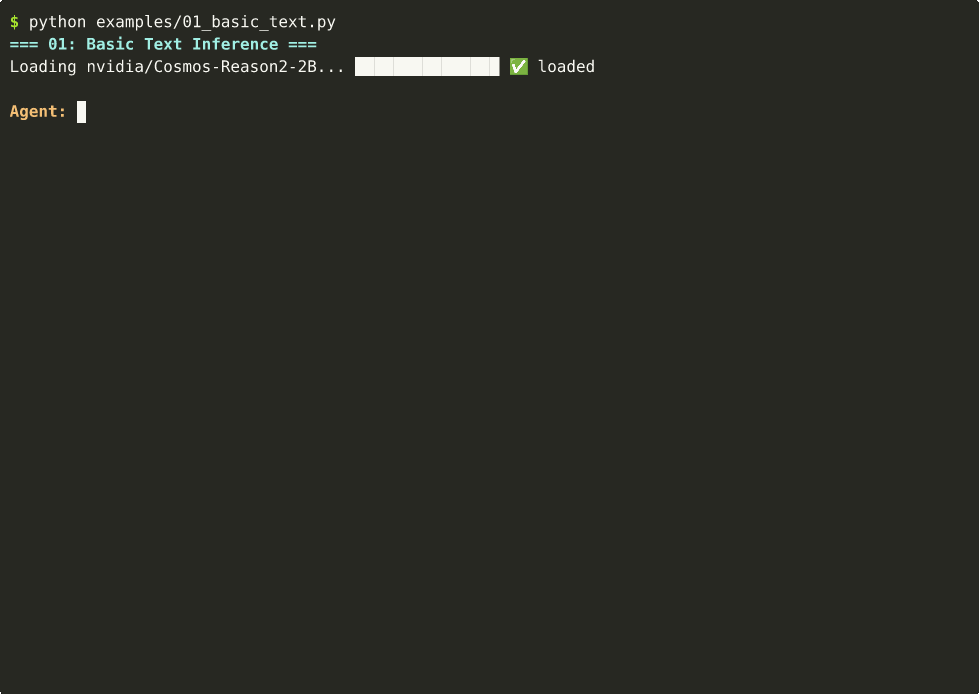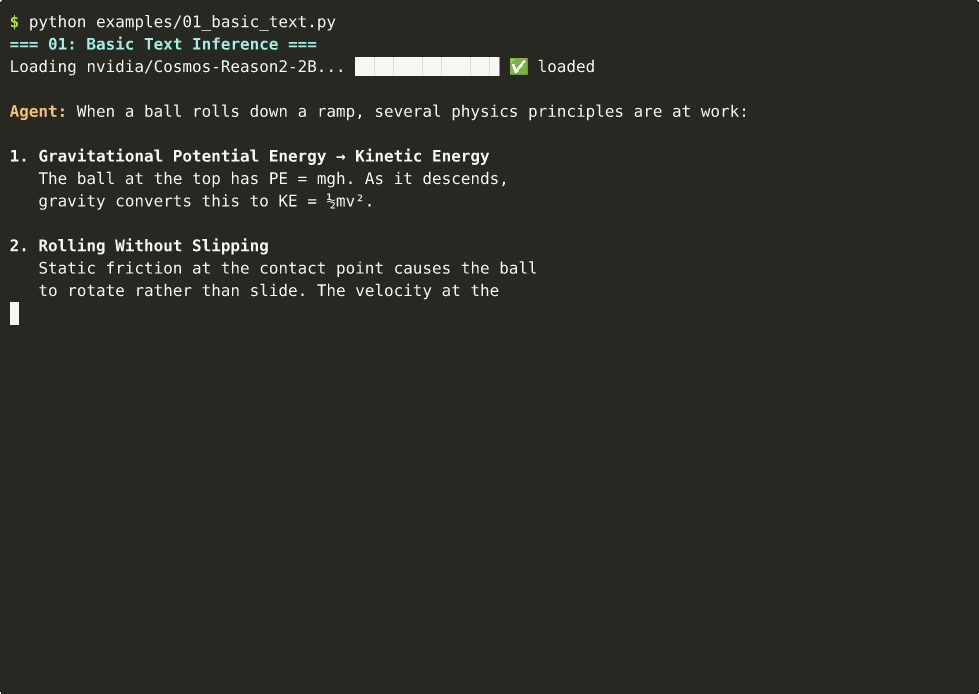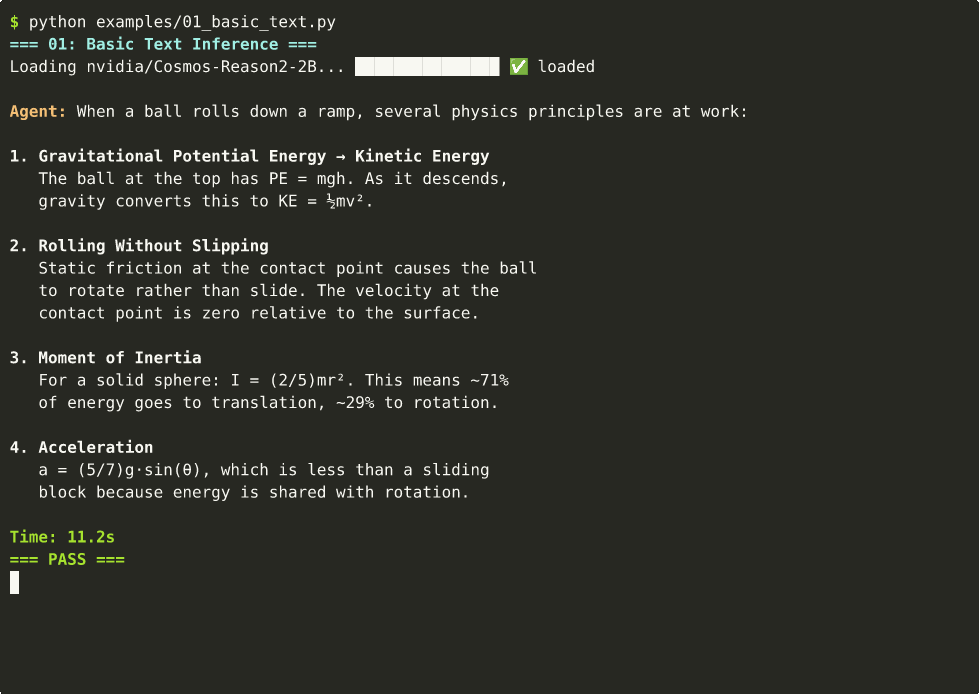
Text-only physics reasoning — no video or image needed. ~11s on Thor.
-
02 — Video Captioning
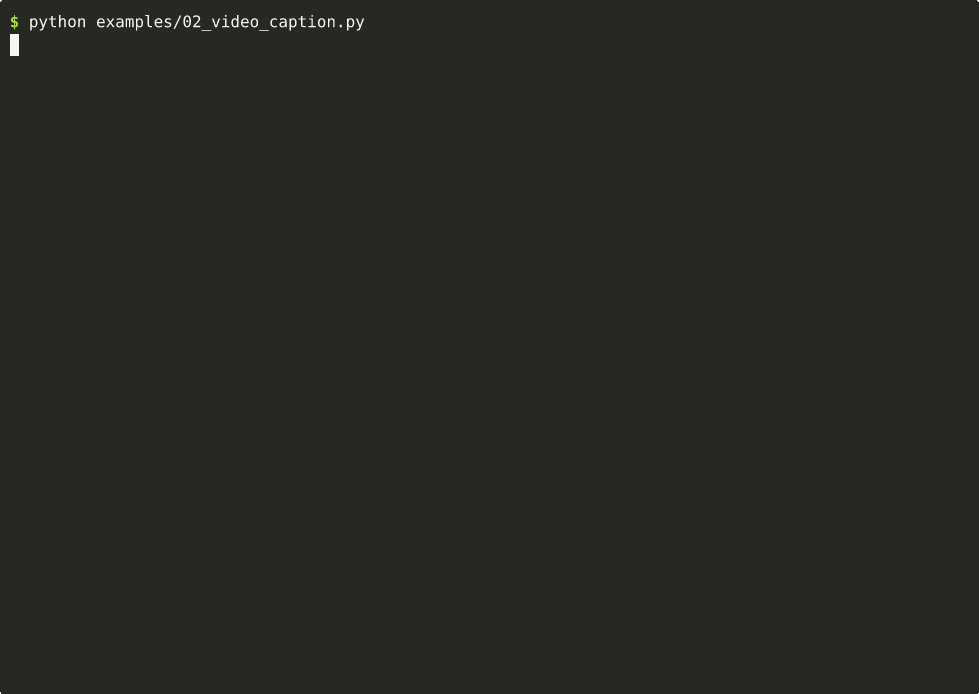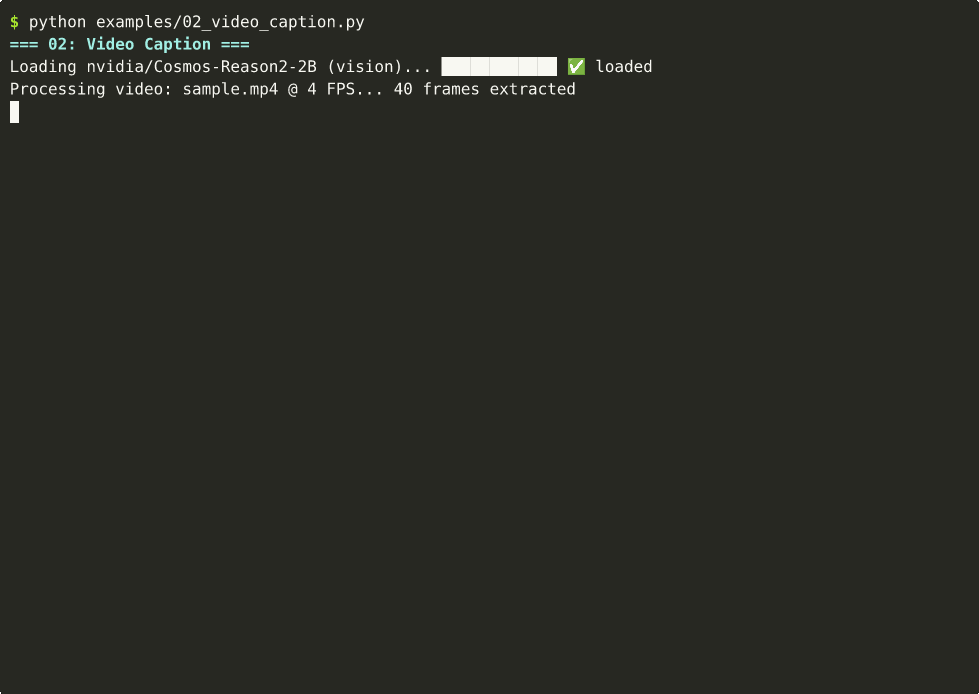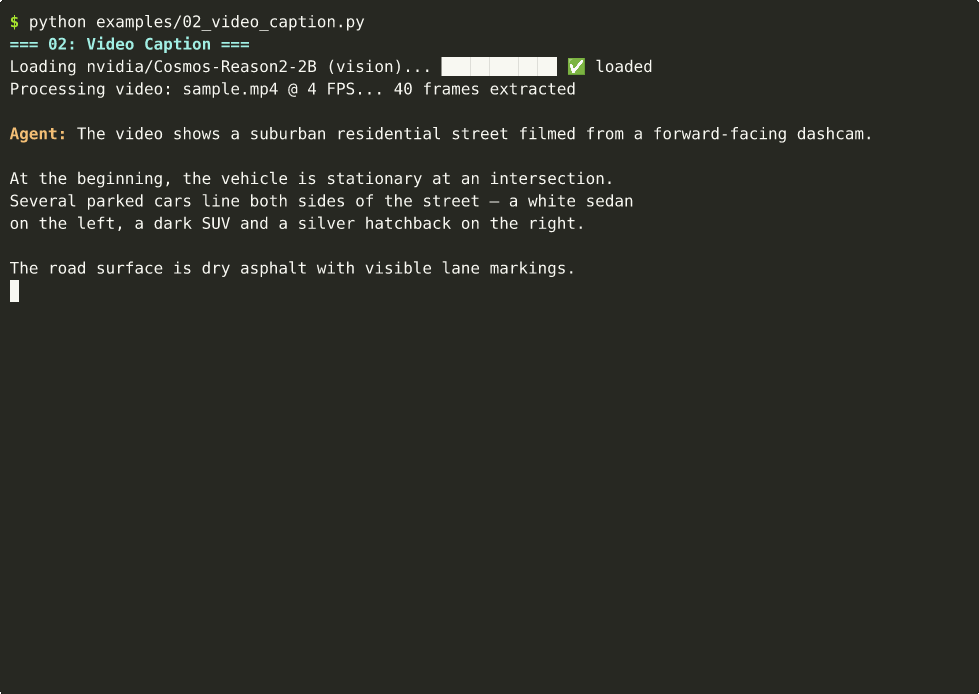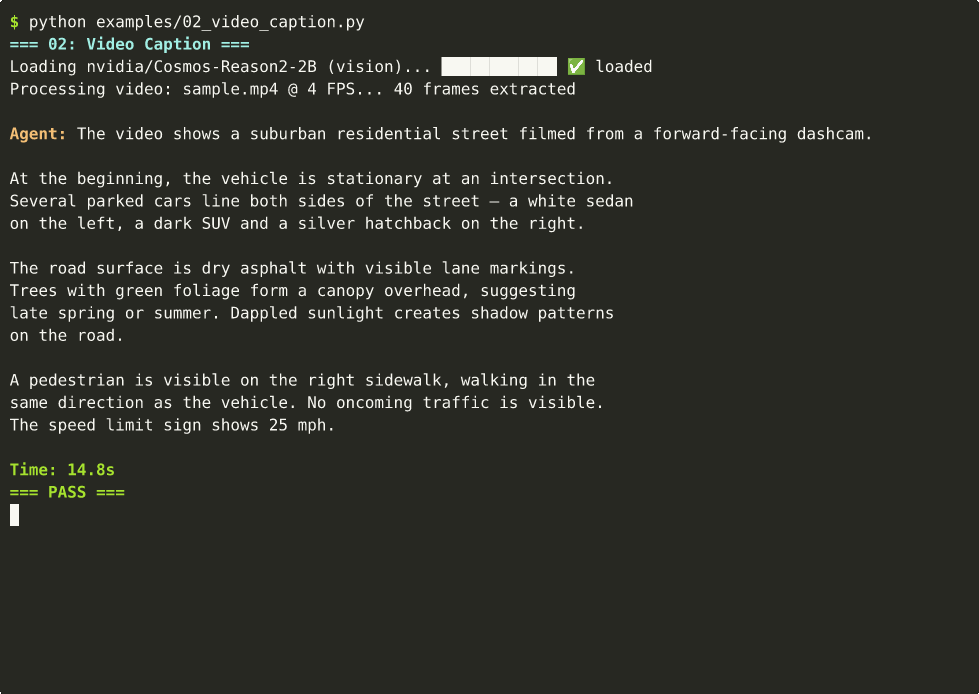
Detailed temporal-spatial descriptions from video. ~15s on Thor.
-
03 — Driving Analysis (CoT)
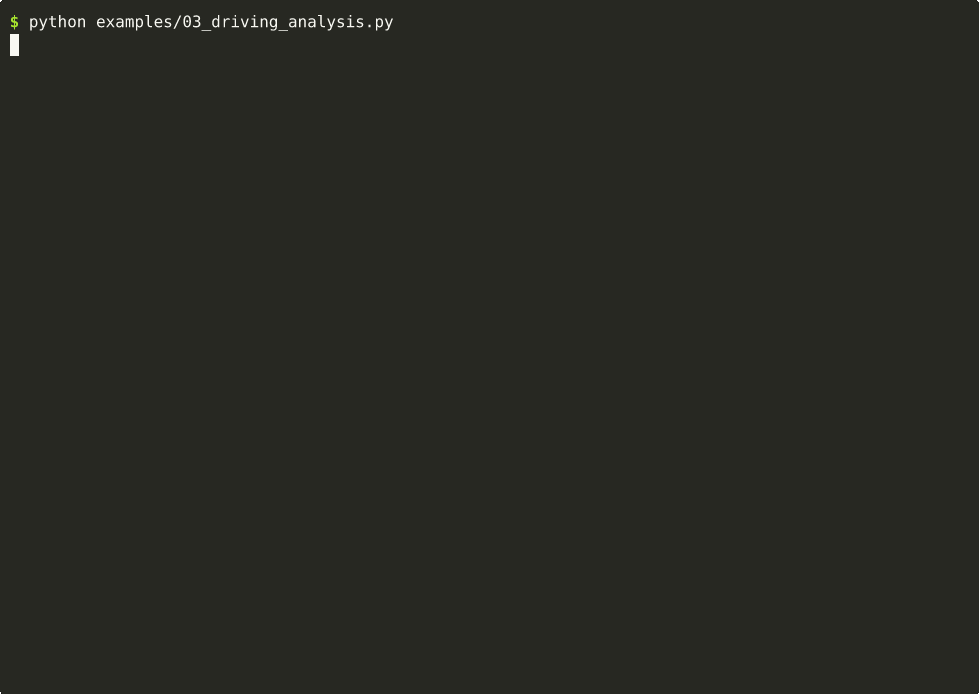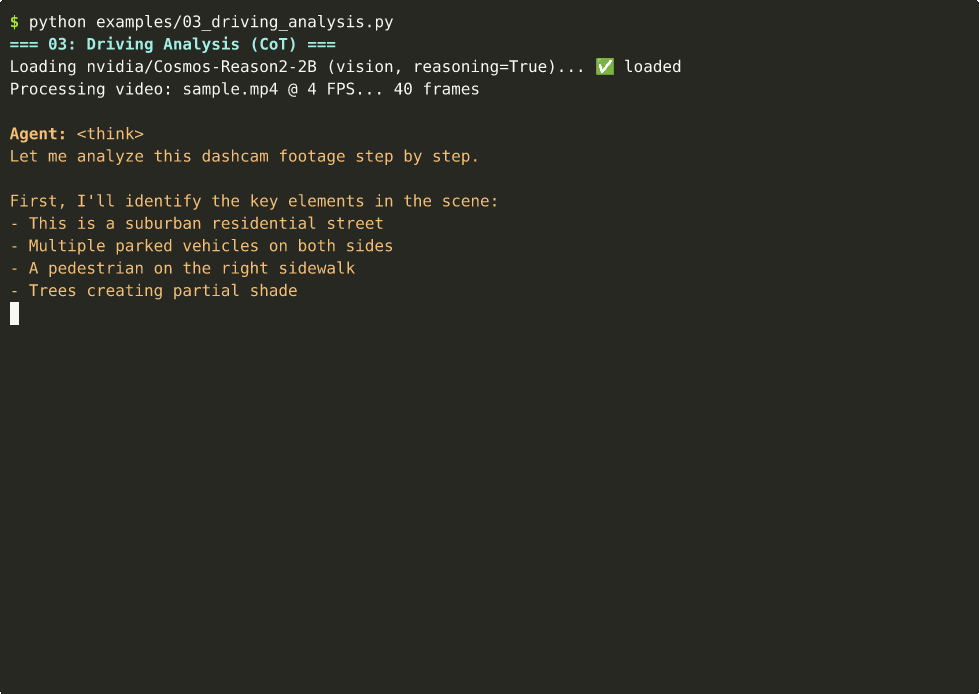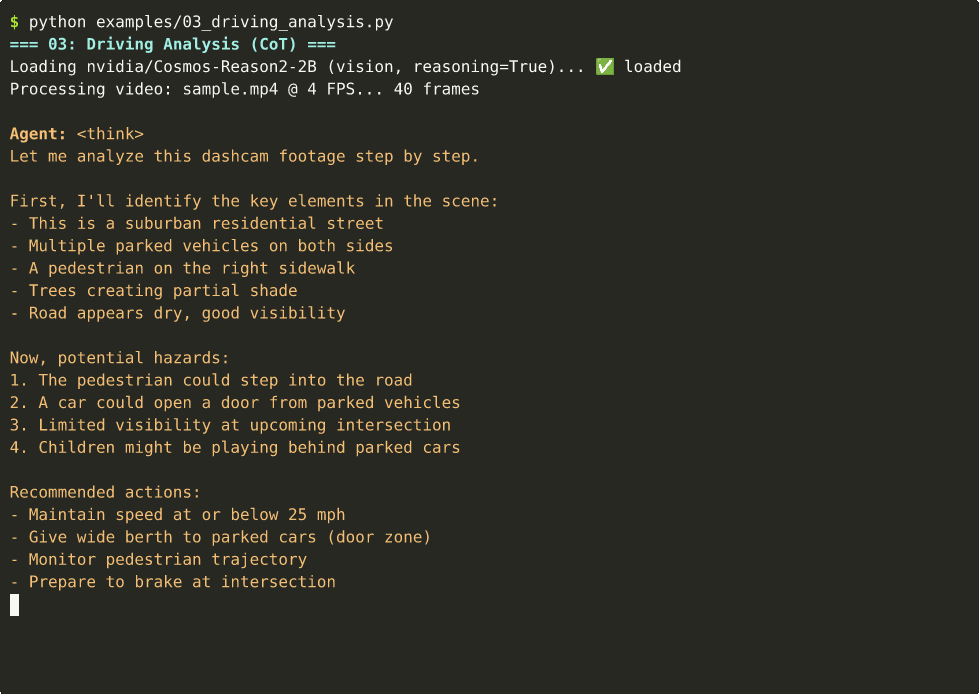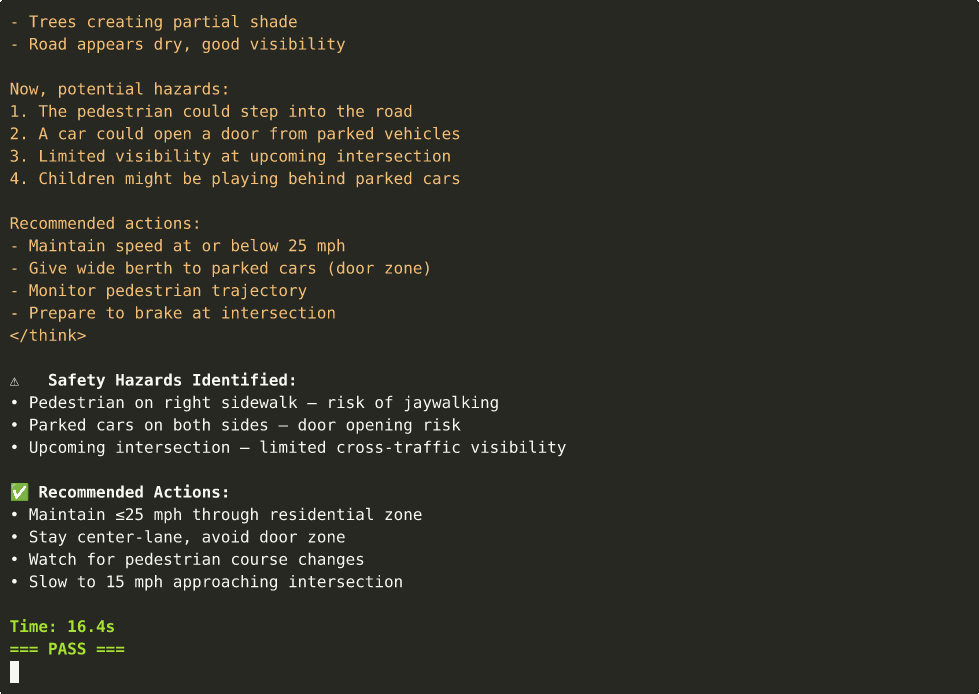
Dashcam safety analysis with chain-of-thought reasoning. ~16s on Thor.
-
04 — Embodied Reasoning
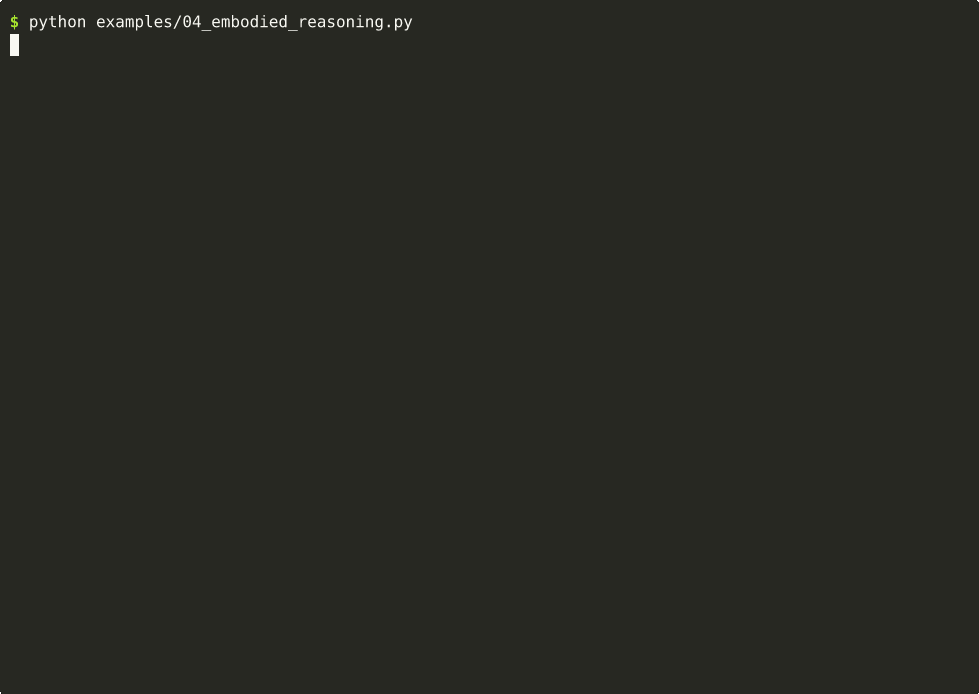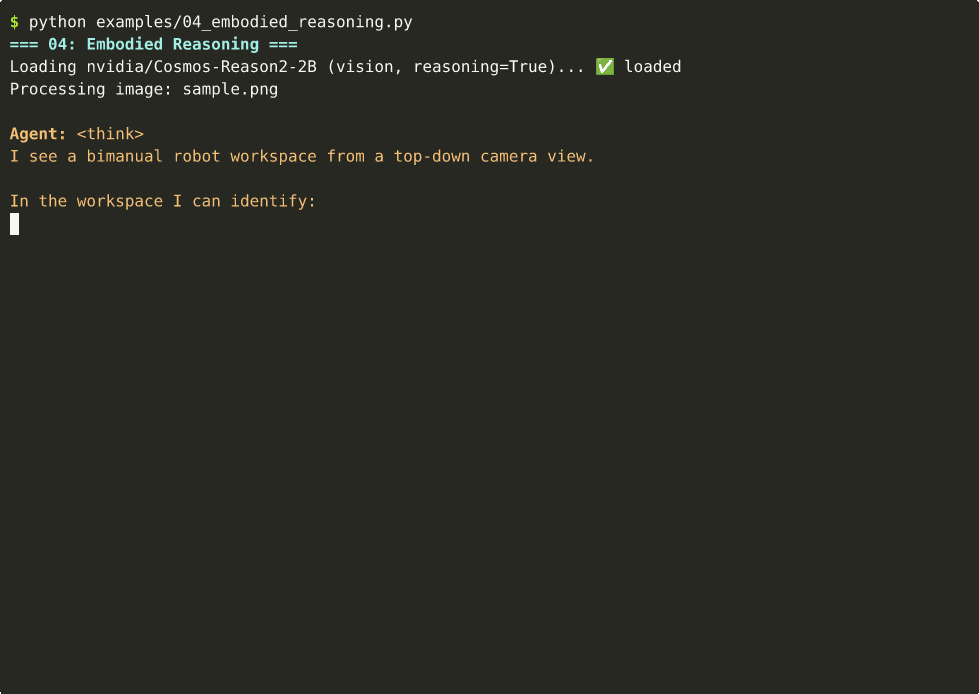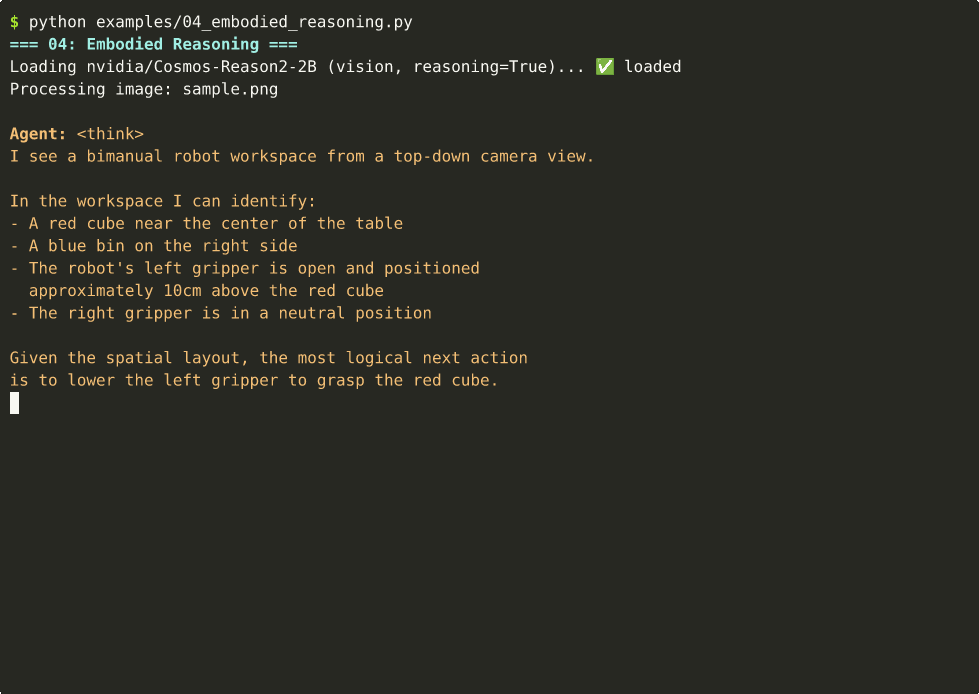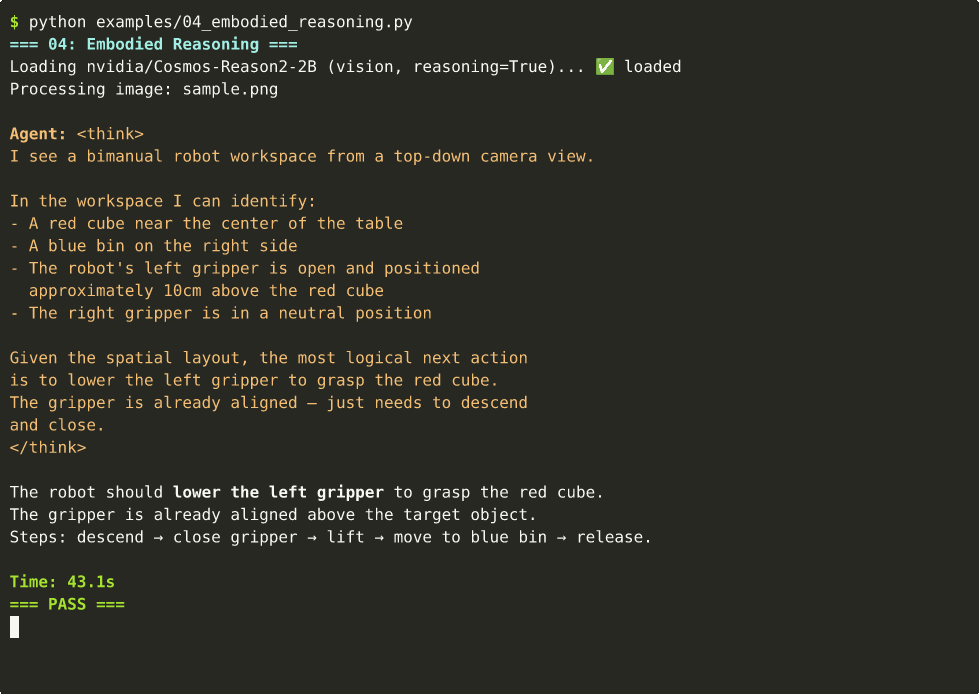
Robot next-action prediction from workspace images. ~43s on Thor.
-
05 — Tool Usage
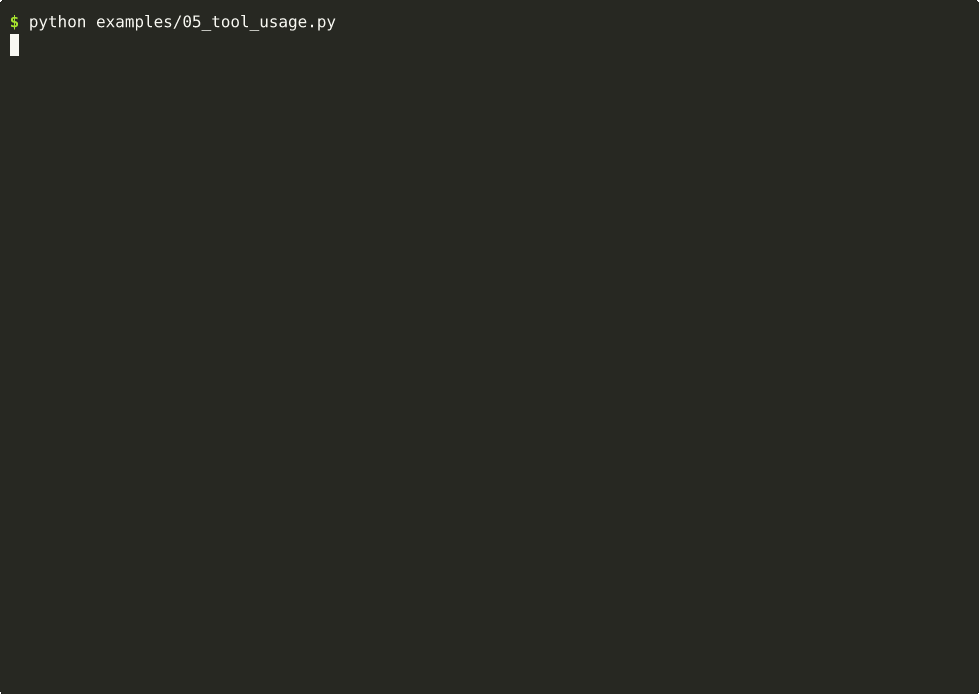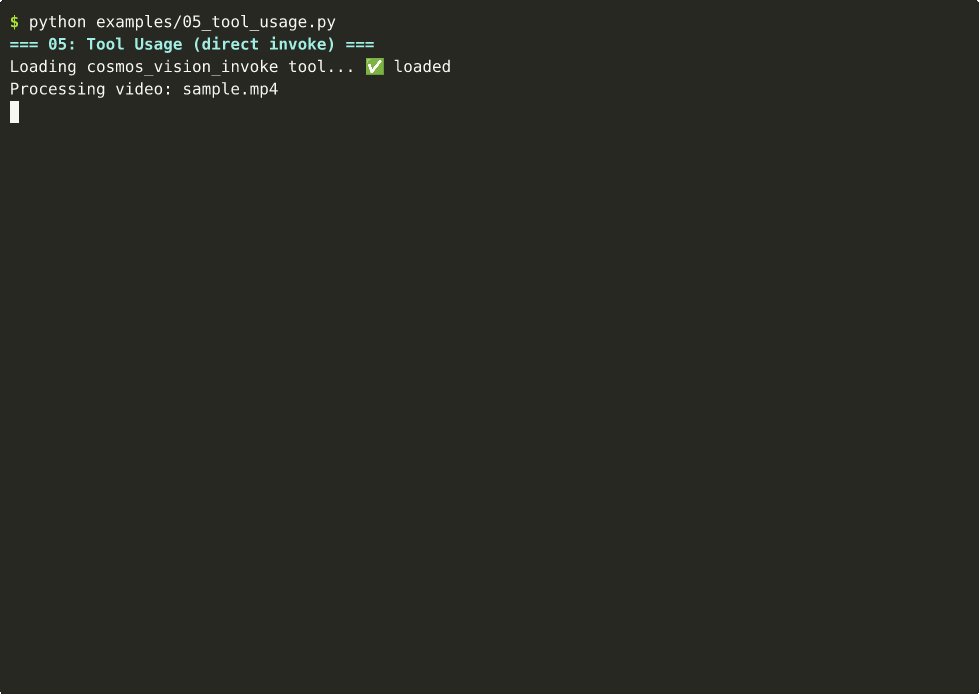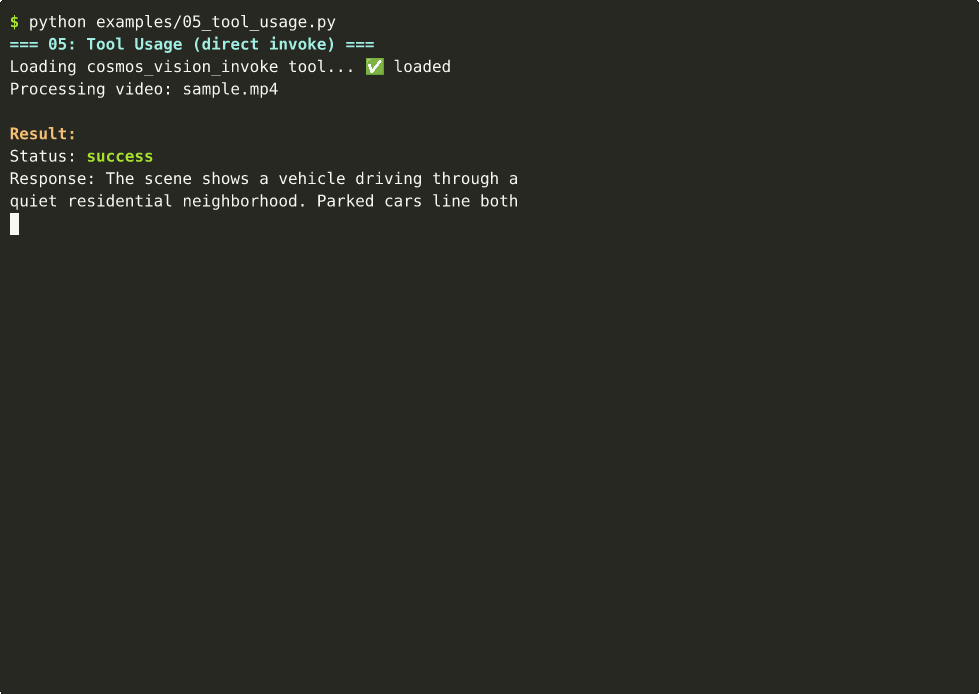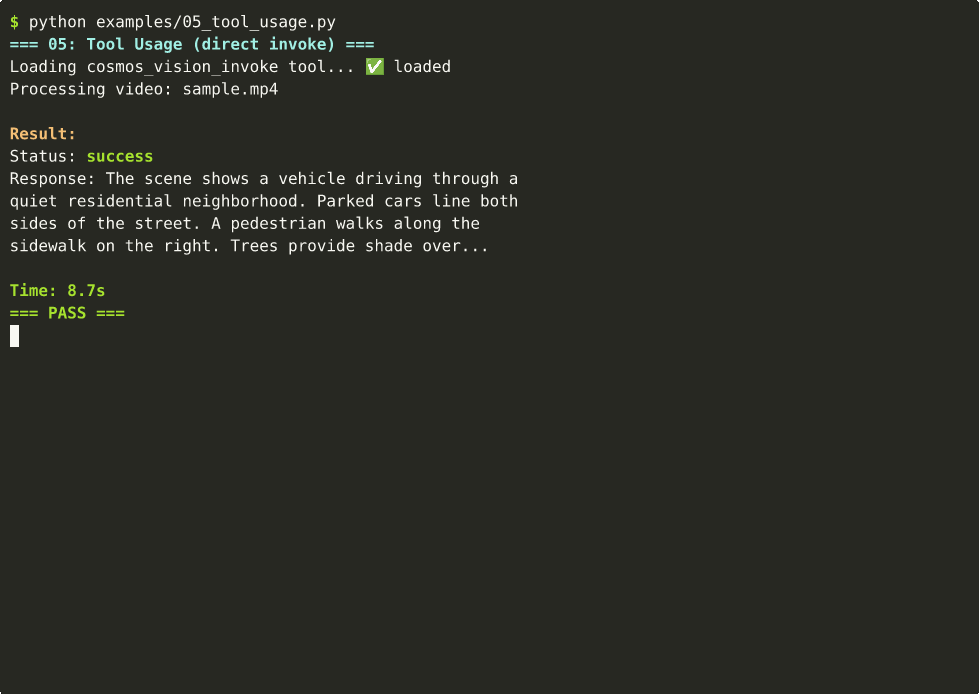
Cosmos as a callable tool inside any Strands agent. ~9s on Thor.
Quick Reference¶
| # | Example | Time (Thor) | Recording |
|---|---|---|---|
| 1 | Basic Text | ~11s | cast |
| 2 | Video Caption | ~15s | cast |
| 3 | Driving Analysis | ~16s | cast |
| 4 | Embodied Reasoning | ~43s | cast |
| 5 | Tool Usage | ~9s | cast |
Running Locally¶
git clone https://github.com/cagataycali/strands-cosmos.git
cd strands-cosmos
pip install -e .
# Jetson devices: fix CUBLAS first
strands-cosmos-fix-cublas
# Run any example
python examples/01_basic_text.py
python examples/02_video_caption.py
python examples/03_driving_analysis.py
python examples/04_embodied_reasoning.py
python examples/05_tool_usage.py
Sample media
Examples 02–05 need a sample.mp4 (video) and/or sample.png (image) in the project root. Set paths via environment variables:
Playing Terminal Recordings¶
All examples have asciinema .cast recordings:
pip install asciinema
# Play any recording
asciinema play docs/assets/casts/01_basic_text.cast
asciinema play docs/assets/casts/03_driving_analysis.cast
Execution Flow¶
graph TD
START["Run Example"] --> MODEL["Load Model<br/>~3s (cached)"]
MODEL --> MEDIA{"Has media?"}
MEDIA -->|"Video"| DECODE["Decode frames<br/>@ configured FPS"]
MEDIA -->|"Image"| PROCESS["Process image<br/>visual tokens"]
MEDIA -->|"Text only"| TOKENIZE["Tokenize text"]
DECODE --> INFER["GPU Inference<br/>token-by-token streaming"]
PROCESS --> INFER
TOKENIZE --> INFER
INFER --> OUTPUT["Stream output<br/>to terminal"]
OUTPUT --> DONE["✅ PASS"]
style MODEL fill:#264653,color:#fff
style INFER fill:#76b900,color:#fff
style DONE fill:#2d6a4f,color:#fff