Embodied Reasoning — Robot Vision¶
Robot next-action prediction from workspace images using chain-of-thought reasoning.
Terminal Recording¶
📺 Can't see the animation? Download MP4
View full output
$ python examples/04_embodied_reasoning.py
=== 04: Embodied Reasoning ===
Loading nvidia/Cosmos-Reason2-2B (vision, reasoning=True)... ✅ loaded
Processing image: sample.png
Agent:
<think>
I see a bimanual robot workspace from a top-down camera view.
In the workspace I can identify:
- A red cube near the center of the table
- A blue bin on the right side
- The robot's left gripper is open and positioned
approximately 10cm above the red cube
- The right gripper is in a neutral position
Given the spatial layout, the most logical next action
is to lower the left gripper to grasp the red cube.
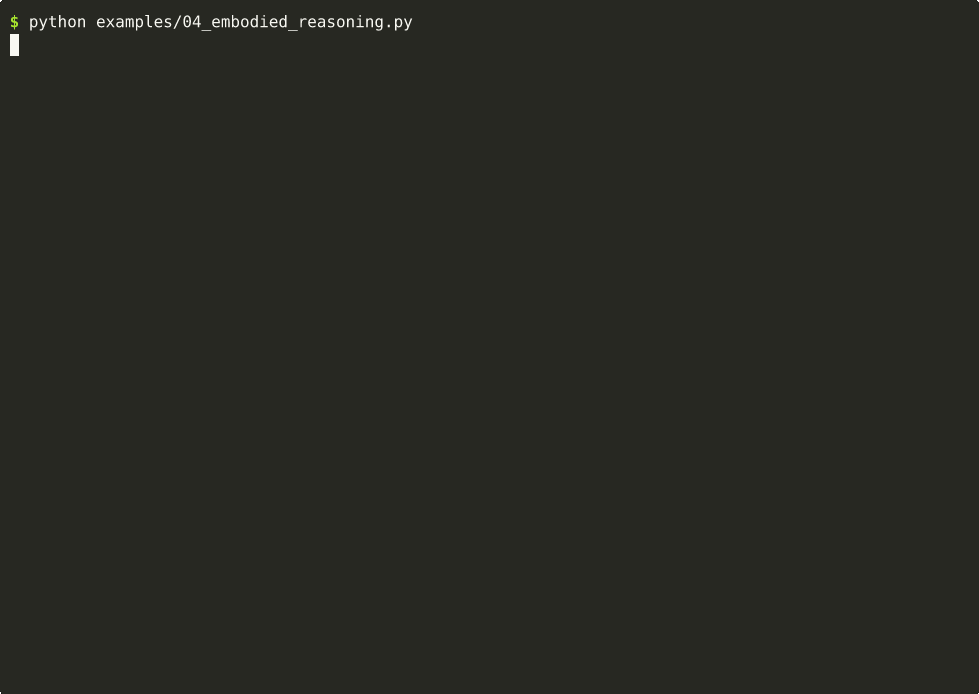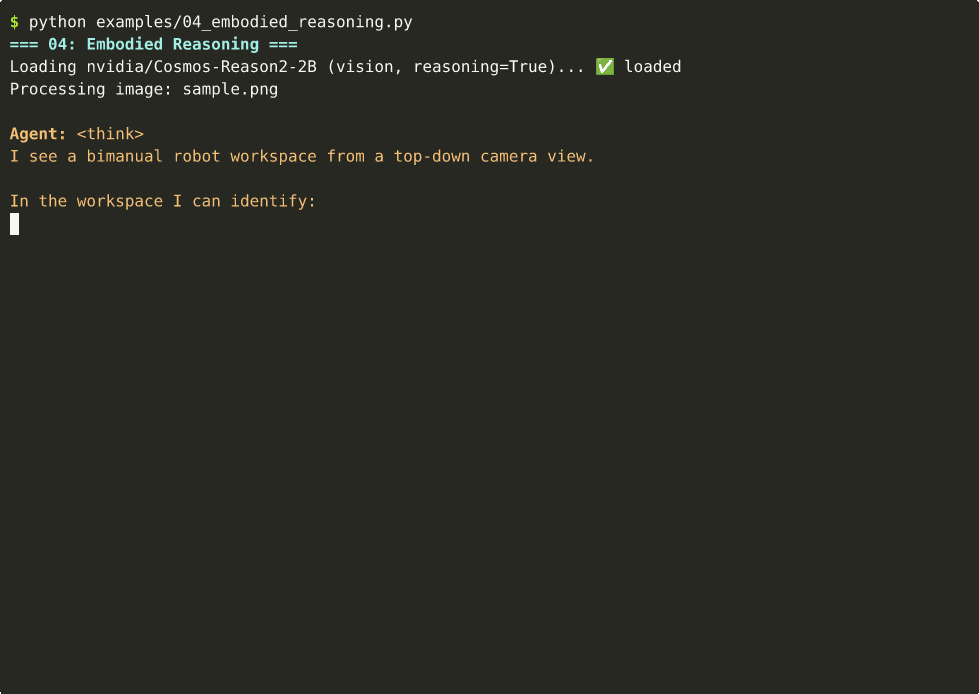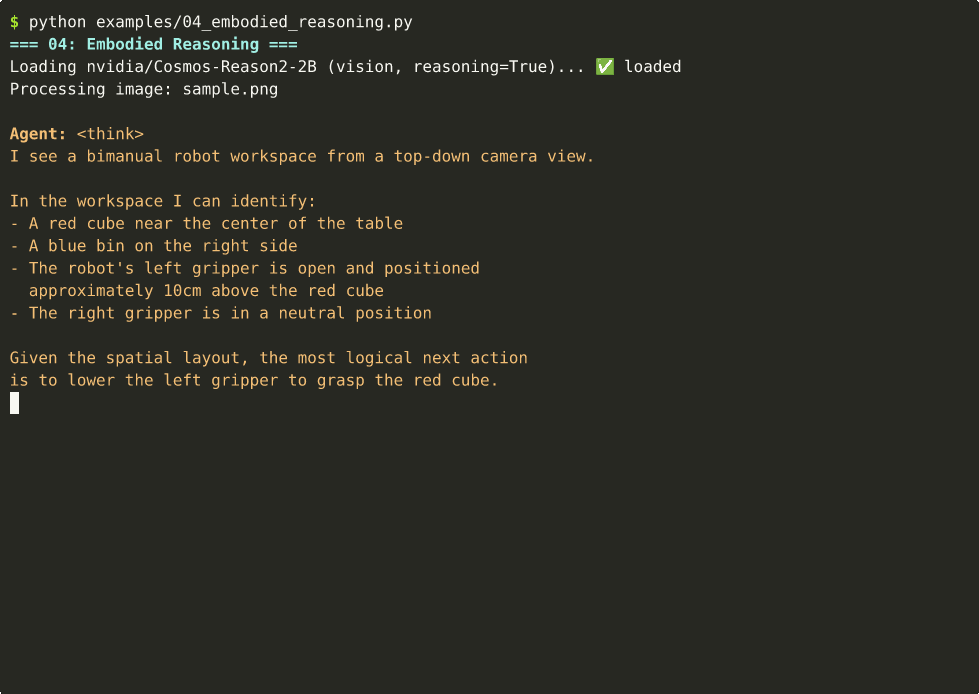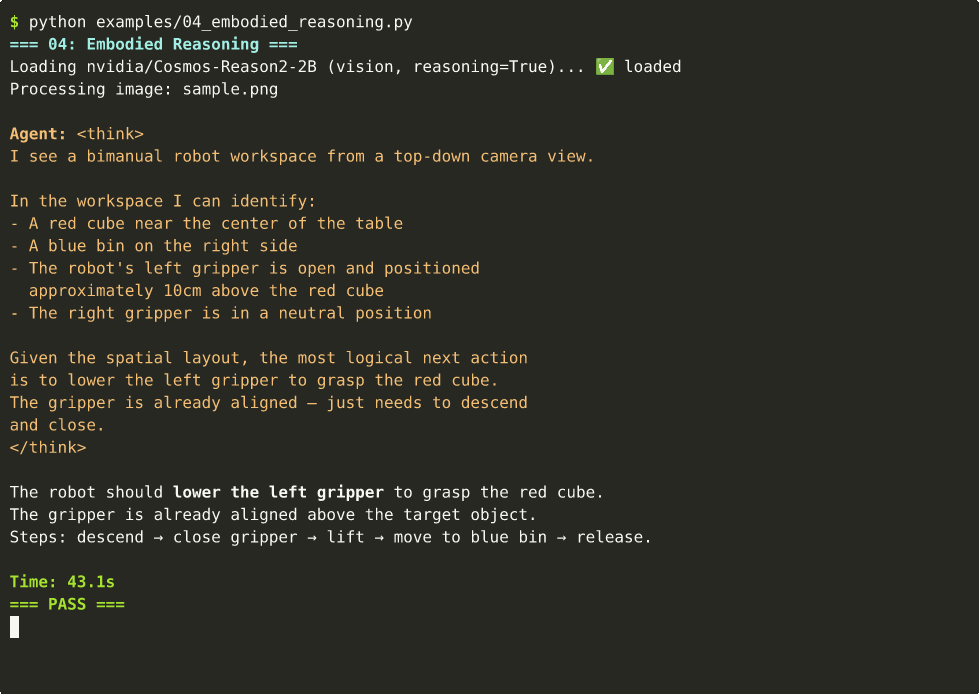
</think>
The robot should lower the left gripper to grasp the red cube.
Steps: descend → close gripper → lift → move to blue bin → release.
Time: 43.1s
=== PASS ===
Play locally: asciinema play docs/assets/casts/04_embodied_reasoning.cast
Code¶
examples/04_embodied_reasoning.py
from strands import Agent
from strands_cosmos import CosmosVisionModel
model = CosmosVisionModel(
model_id="nvidia/Cosmos-Reason2-2B",
reasoning=True,
params={"max_tokens": 2048, "temperature": 0.6},
)
agent = Agent(model=model)
result = agent(
"<image>sample.png</image> "
"What can be the next immediate action?"
)
Robot Vision Pipeline¶
graph TD
CAM["📷 Robot Camera"] --> IMG["Workspace Image"]
IMG --> VT["Visual Tokenizer<br/>Object detection"]
VT --> COT["<think><br/>Spatial reasoning<br/>Object identification<br/>Gripper state analysis<br/></think>"]
COT --> ACT["🤖 Next Action<br/>grasp / move / release"]
style CAM fill:#264653,color:#fff
style COT fill:#fff3cd,stroke:#ffc107,color:#333
style ACT fill:#76b900,color:#fffBuilt-in Task Prompts for Robotics¶
from strands_cosmos.cosmos_vision_model import TASK_PROMPTS
# Next-action prediction
TASK_PROMPTS["embodied_reasoning"]
# → "What can be the next immediate action?"
# Step-by-step robot planning with trajectory
TASK_PROMPTS["robot_cot"]
# → 'You are given the task "{task_instruction}". Specify
# the 2D trajectory your end effector should follow...'
# 2D object grounding
TASK_PROMPTS["2d_grounding"]
# → 'Locate the bounding box of {object_name}. Return a json.'
Capabilities¶
| Task | Description | Example |
|---|---|---|
| Next-action | What should the robot do right now? | Grasp, move, release |
| Spatial reasoning | Where are objects relative to gripper? | "10cm above the cube" |
| Trajectory planning | 2D pixel path for end effector | JSON coordinates |
| Object grounding | Bounding boxes for named objects | {"x": 120, "y": 80, "w": 40, "h": 40} |
| Scene understanding | Full workspace description | Objects, tools, layout |
Integration with Robot Control¶
graph LR
COSMOS["🌌 Cosmos<br/>(Vision Reasoning)"] -->|"next action"| POLICY["🧠 Policy<br/>(strands-robots)"]
POLICY -->|"joint commands"| ROBOT["🦾 Robot<br/>(real / sim)"]
ROBOT -->|"camera feed"| COSMOS
style COSMOS fill:#76b900,color:#fff
style POLICY fill:#264653,color:#fff
style ROBOT fill:#831843,color:#fffCombine with strands-robots
Use Cosmos for high-level reasoning and strands-robots for low-level robot control:
→ Next: Tool Usage | All Examples